Federated Learning: Train AI Without Moving Data
Scaleout
Most AI systems are built on a simple but increasingly problematic assumption: that the data needed to train a model can be collected and moved to a central location. For much of AI’s history, that assumption held. Today, in a growing number of important applications, it does not.
This article explains what federated learning is, why it exists, how it works, and where it is making a real difference. It also covers what it does not solve, and when it may not be the right approach.
The Way AI Training Has Always Worked
Training an AI model requires data, typically a lot of it. In the standard approach, that data is collected from wherever it originates and moved into a central repository: a cloud environment, a data centre, a shared database. Once consolidated, algorithms are applied, the model learns from the full dataset, and the trained model is deployed wherever it is needed.
This works well when data can move freely. For many applications — recommending films, detecting spam, translating text — it can, and the results have been impressive.
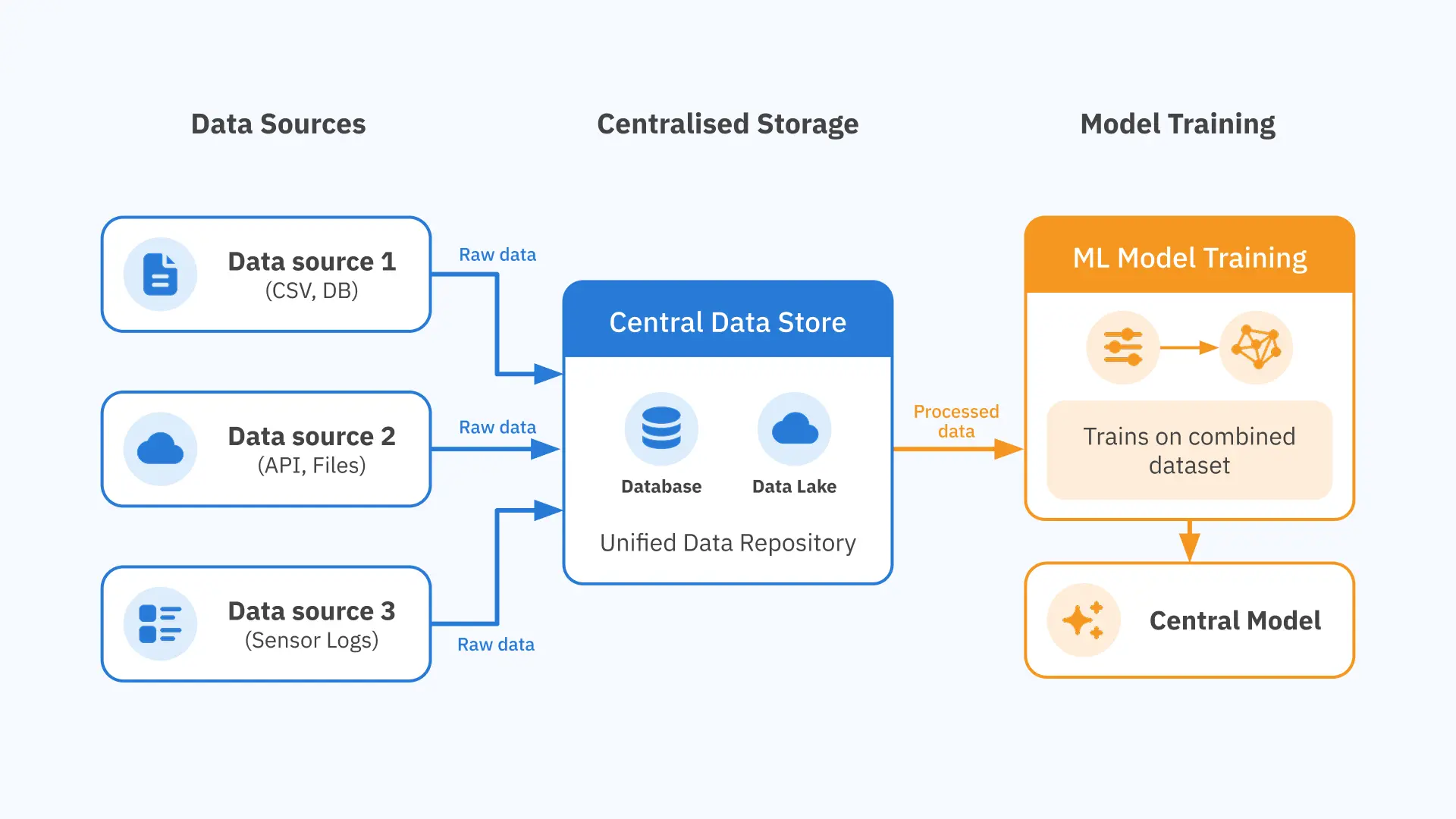
The centralised model depends on one thing: that data can leave its source. Increasingly, that is not true.
Why Centralising Data Is No Longer Always Possible
Several distinct pressures are breaking this assumption down.
- Privacy law and regulation. In healthcare, finance, and government, data is subject to strict regulations: GDPR in Europe, HIPAA in the United States, and equivalent frameworks elsewhere. Patient records, financial transactions, and personal communications cannot be freely moved or shared. Centralising this data for AI training either violates those regulations or requires expensive anonymisation that tends to degrade data quality.
- Classification and sovereignty. In defence and intelligence contexts, data may be classified. Moving it to a shared environment, even a secure one, may be prohibited outright. Some data simply cannot cross institutional or jurisdictional boundaries under any circumstances.
- Volume and bandwidth. Modern systems — vehicles, industrial sensors, drones, surveillance infrastructure — generate data at scales that make centralisation impractical. Transmitting terabytes of sensor data continuously to a central server is slow, expensive, and in many environments not feasible at all.
- Competitive sensitivity. Competing companies in the same industry might benefit from training a shared model, but they hold data that is commercially sensitive. Even where regulations would permit it, business considerations usually do not.

The result is a growing gap: data that would be valuable for AI training exists, but cannot be moved to where training has traditionally happened.
The Core Idea: Move the Model, Not the Data
Federated learning addresses this gap by inverting the conventional workflow.
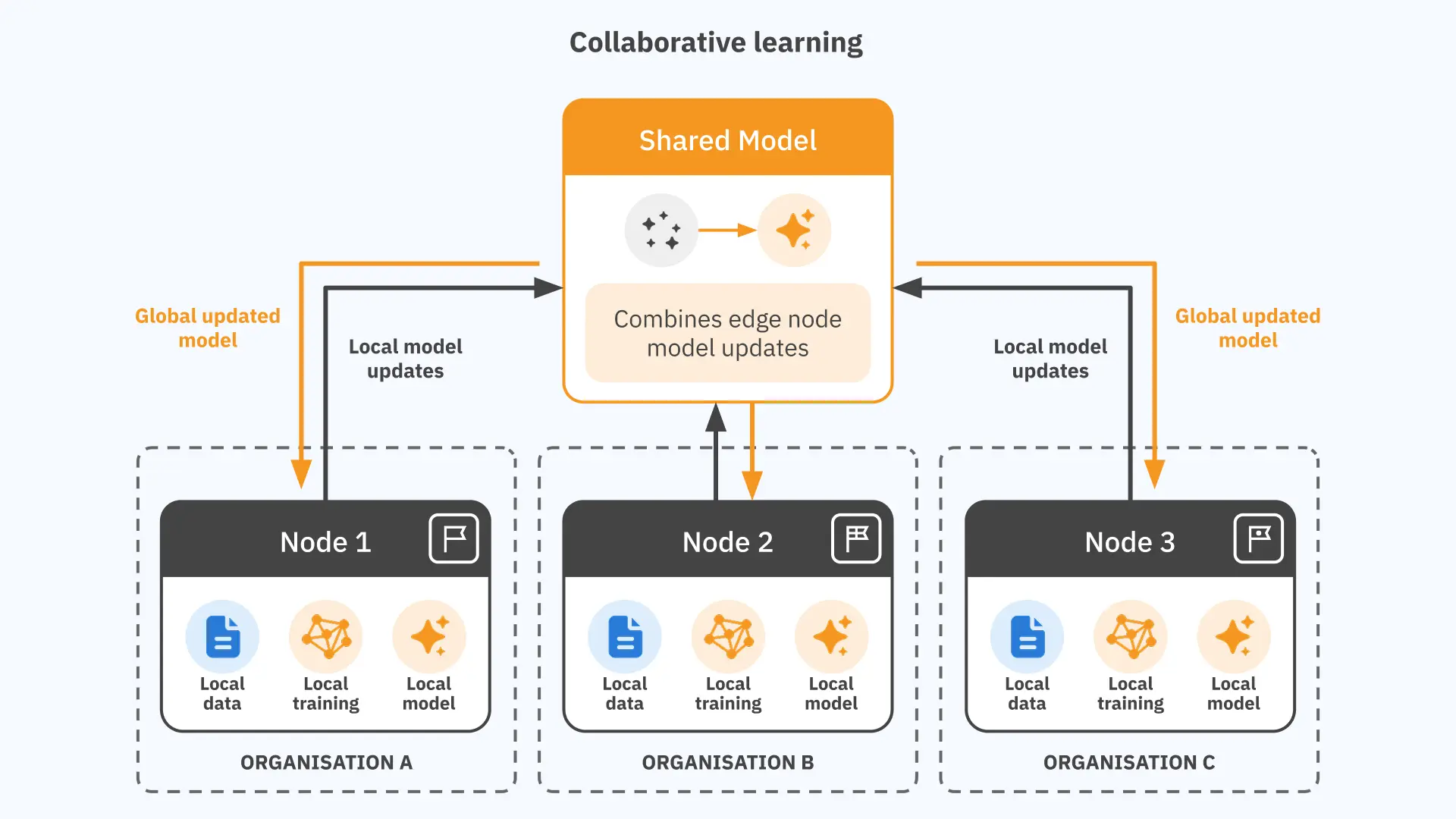
Instead of moving data to a central location, federated learning sends the model to where the data already lives. Each participating node — a device, a server, a site — trains the model locally on its own data. Only the results of that local training, a set of mathematical adjustments to the model’s parameters, are sent back to a central point and combined into an improved global model.
The raw data never moves. It never leaves the device, the site, or the jurisdiction where it was generated.
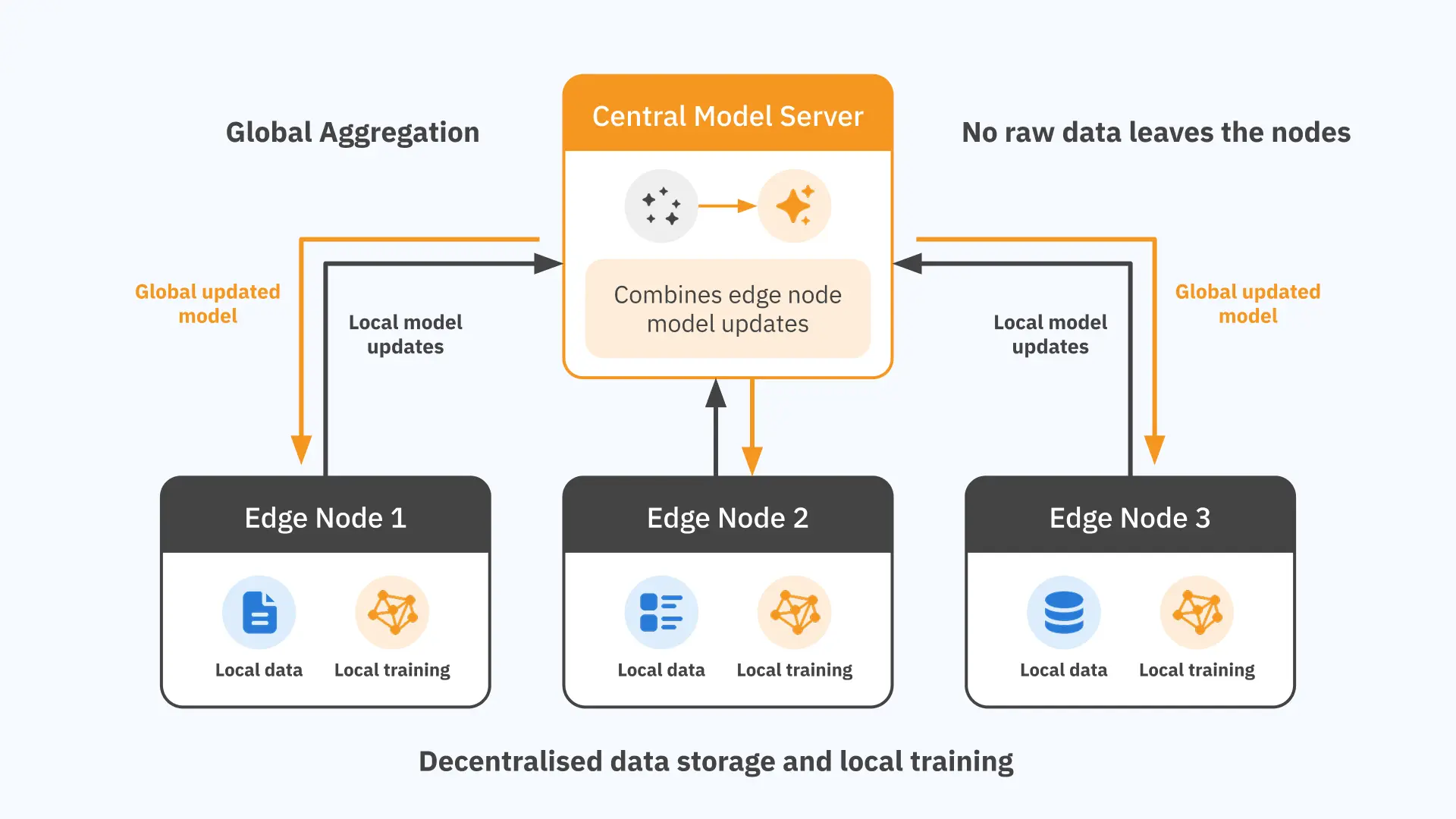
This reversal — model to data rather than data to model — is the core idea. Everything else follows from it.
How a Training Round Works
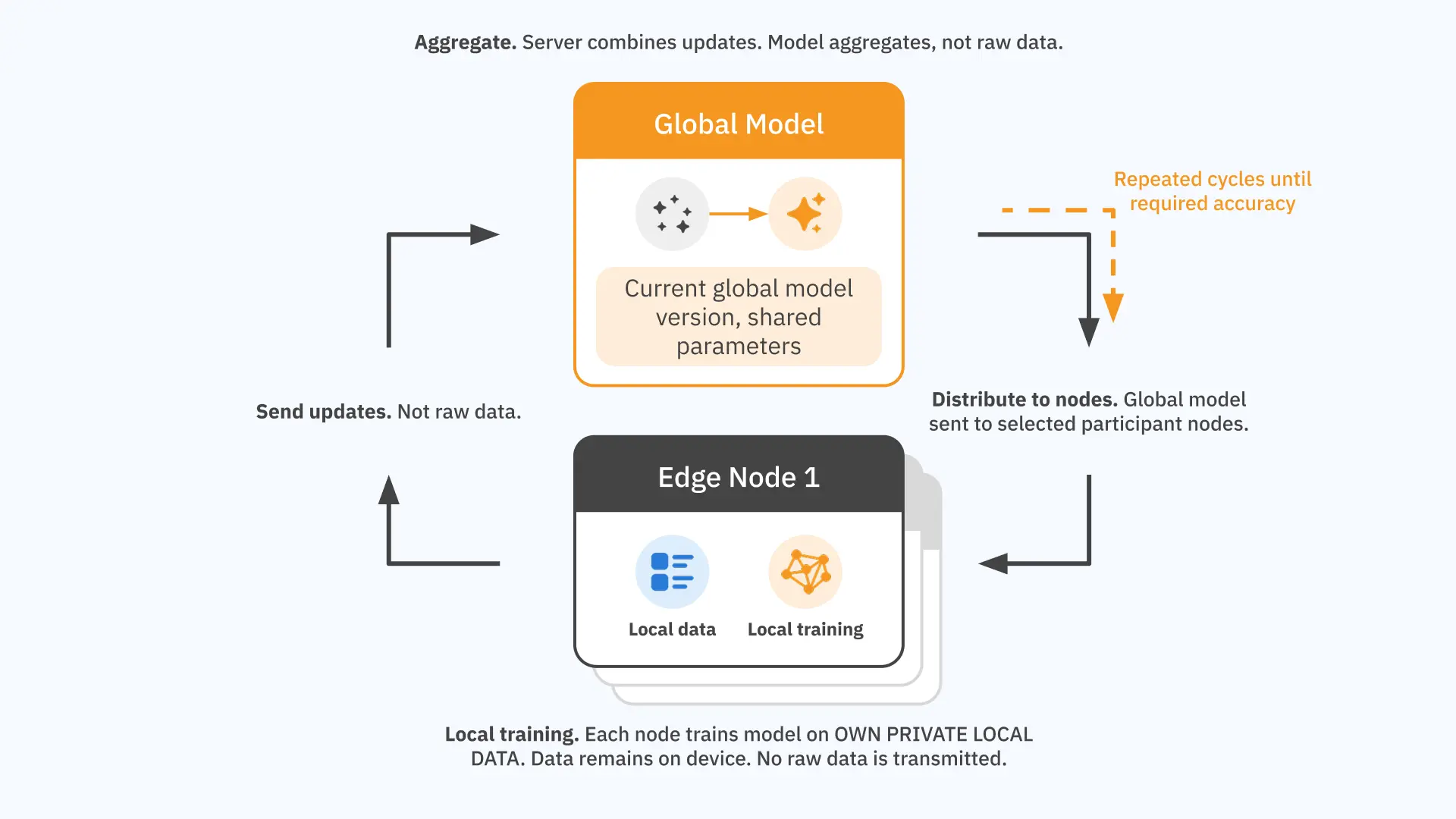
Federated learning proceeds in repeated cycles called rounds. Each round follows the same sequence.
- Distribution. The current version of the global model is sent from the central server to a selected group of participating nodes.
- Local training. Each node trains the model on its own local data. This computation happens entirely on the node. Nothing about the local data is transmitted anywhere.
- Update submission. Each node sends its model update back to the central server. The update is a compact mathematical representation of what the model learned, not the data itself. The difference in size matters: a model update might be kilobytes or megabytes; the raw data that produced it might be terabytes.
- Aggregation. The central server combines the updates from all participating nodes into a new, improved global model. The most common baseline method is a weighted average (known as FedAvg), where nodes that trained on more data contribute proportionally more to the result. More sophisticated aggregation strategies exist and are often used in practice, particularly when data distributions differ significantly across nodes.
- Next round. The improved model is sent back to the nodes, and the cycle repeats until the model reaches the required level of accuracy.
Not every node needs to participate in every round, and nodes do not need to be online simultaneously. If a device goes offline mid-round, training continues with whatever nodes are available; when it reconnects, it receives the current global model and rejoins the next round. In deployments where connectivity cannot be guaranteed, this tolerance for intermittent participation matters more than it might initially seem.
What Actually Travels, and What Doesn’t
The privacy properties of federated learning follow directly from what is and is not transmitted.
The only thing that travels from a node to the server is a model update: a set of numerical adjustments to the model’s weights, representing what was learned during local training. The underlying data — patient records, sensor readings, transaction logs, audio files — stays on the node.
This is not a policy commitment or an access control setting. It is a consequence of how the system is designed. There is no mechanism by which the raw data is transmitted, because the architecture does not require it.
Federated learning is therefore classified as a Privacy-Enhancing Technology (PET): a category of approaches that build privacy into their design rather than relying on rules about how data should be handled.
Two Patterns of Collaboration
Federated learning enables two distinct types of collaborative AI, each solving a different problem.
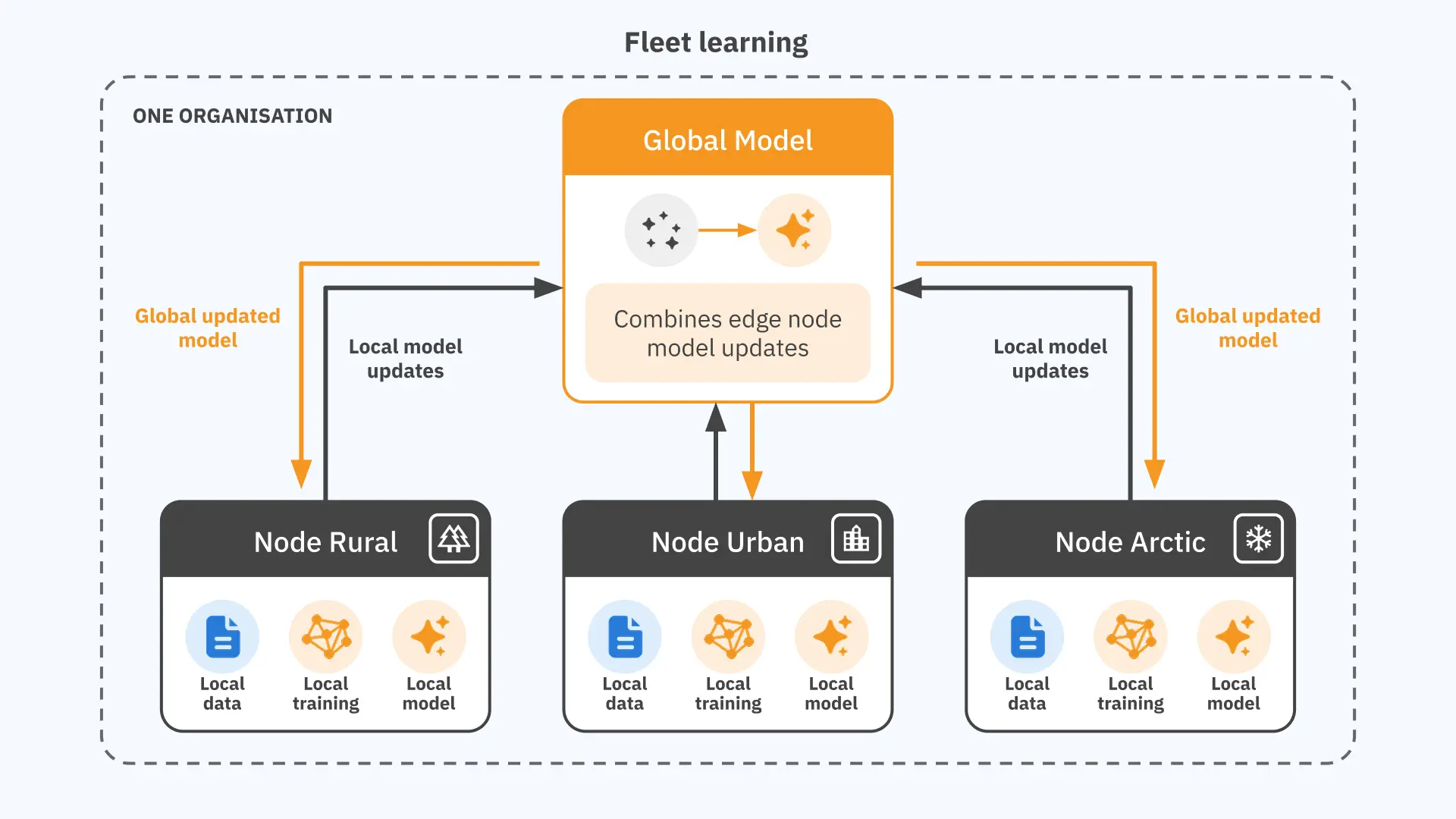
Fleet learning (one organisation, many devices). A single organisation owns both the model and the data, but the data is spread across devices or sites that cannot or should not centralise it. A vehicle manufacturer wants to improve its autonomous driving models using real-world driving data from its entire fleet, but transmitting raw video from every vehicle is impractical, and that data includes information about individual drivers and routes. A company running industrial equipment across remote sites faces a similar problem with predictive maintenance: the sensor data is valuable, but volume and connectivity make centralisation unworkable. Federated learning lets the model improve from the full fleet’s experience without data leaving any individual device or site.
Cross-organisation collaboration (multiple parties, shared goal). Multiple organisations, each holding data they cannot share, jointly train a model better than any could build alone. Hospitals in different countries might collaborate on a diagnostic model drawing on patient data from all of them, but that data cannot cross institutional or national borders. Banks face a version of the same problem with fraud detection: transaction patterns across the industry would improve any individual bank’s model, but sharing that data with competitors is neither legally permissible nor commercially acceptable. Federated learning makes the collaboration possible without any party seeing another’s data.
The outcome in both cases is a model trained on more data than any single participant could access, without that data being pooled or transferred.
What Federated Learning Does Not Solve
Federated learning addresses the data movement problem. It does not eliminate every privacy and security concern. Understanding these limitations is important for anyone evaluating whether it is the right approach for a given use case.
- Model updates can carry information. The updates sent from nodes to the server are derived from training data. Under certain conditions, a sophisticated adversary with access to those updates could attempt to reconstruct something about the underlying data, through a class of attacks known as gradient inversion. The risk is lower than the risk of transmitting raw data, and techniques such as differential privacy can reduce it further, but it is not zero. The probability varies with model architecture, dataset size per node, and update frequency. Organisations handling sensitive data should treat this as a real design consideration, not an afterthought.
- The server sees individual updates. The central server receives and processes individual updates from each node. Even if raw data never travels, the server can still observe which nodes contributed updates and when. Secure aggregation — a cryptographic technique that allows the server to compute the aggregate without seeing individual node updates — addresses this, but adds implementation complexity.
- Malicious or faulty nodes. In any distributed system, some nodes may behave incorrectly, due to hardware faults, software bugs, or deliberate manipulation. A malicious node can submit poisoned updates designed to degrade the global model or introduce specific misbehaviours — a threat known as model poisoning. Robust aggregation methods exist to limit the influence of outlier updates, but this is an active area of research, not a solved problem.
- Coordination is complex. Training across many distributed nodes with intermittent connectivity, varying hardware, and uneven data is operationally harder than centralised training. It requires infrastructure built for the purpose.
- Uneven data across nodes can slow learning. When nodes hold data reflecting very different local conditions — which is common, and known as non-IID (non-independently and identically distributed) data — convergence can take longer than in centralised training, and the resulting model may perform unevenly across nodes. Standard aggregation handles this poorly. More sophisticated methods exist but add complexity.
These are known engineering and research challenges, not fatal flaws. But federated learning is sometimes described as a complete privacy solution, and that overstates what it provides.
When Federated Learning May Not Be the Right Choice
Federated learning solves a specific problem: training across data that cannot be centralised. It is not always the best solution, even when centralisation is difficult.
If the privacy concern is primarily about who can query or access a trained model rather than where training data lives, other approaches — access controls, model auditing, output filtering — may be simpler and more effective.
If data can be anonymised or synthesised without significant loss of utility, centralised training on anonymised or synthetic data may be preferable. Federated learning introduces operational complexity that is only worth it when that complexity is the cheaper option.
If nodes have very small or highly uneven datasets, the model may not converge well, and the federated approach may yield a worse model than centralised training on a smaller but more uniform dataset would.
If the regulatory constraint is about output (what the model can reveal) rather than input (where training data lives), federated learning does not address the underlying concern.
The right question is not whether federated learning is technically applicable, but whether it is the most practical route to the outcome required.
Why This Matters Now
The gap federated learning addresses is not closing. Data regulation is tightening. The volume of data produced at the edge — by vehicles, devices, sensors, and infrastructure — keeps outpacing the capacity to centralise it. And the data AI most needs to learn from tends to be the most protected: medical records, operational logs, financial transactions, security-relevant signals.
The domains where this tension is sharpest are also the ones where AI has the most to offer: medical diagnosis, autonomous systems, industrial operations, defence. These are not peripheral applications. Centralised approaches hit hard limits in all of them, limits that are not going away.
Federated learning does not solve every distributed AI problem. But it removes the one constraint that has blocked progress most often: the requirement to move data before you can learn from it. For organisations operating in data-sensitive environments, it is a tool worth understanding well, including its limits.
For a deeper look at how federated learning is implemented as infrastructure for edge AI, see the Scaleout Edge Platform Overview. For technical architecture and deployment details, see the Technical Brief. Images can be found in Federated Learning Illustrations.