In federated machine learning, one of the biggest challenges is ensuring that models continue to adapt and improve without overwhelming the system with unnecessary or redundant data. Sending raw video streams from drones, autonomous systems, or surveillance devices to a central server is not an option, as it raises bandwidth, privacy, and latency issues.
The solution is data selection on the edge. By filtering and curating data directly on the device, we ensure that only the most relevant and informative samples are used for training, while the raw data itself never leaves the device. With Scaleout Edge as the federated learning backbone, these locally curated datasets fuel adaptive improvements to a global model through federated aggregation.
This post outlines how our data selection pipeline works, from live video capture to federated training.
Adaptive Data Selection Pipeline
The pipeline is designed to automatically discard redundant or uninformative frames and prioritize those that are valuable for model improvement. Importantly, the thresholds, filters, and model choices can be tuned for each use-case and data stream, whether drones monitoring roads, fixed surveillance cameras in cities, or autonomous vehicles on the move.
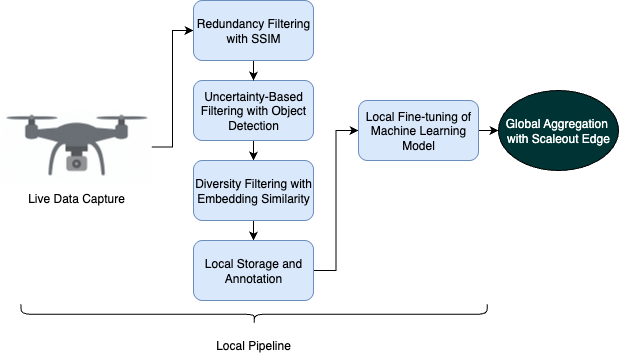
1. Live Data Capture
The pipeline begins with live video input from an edge device such as a drone. Rather than saving every frame, the system samples frames at regular intervals to reduce computational load and storage use. The developer can use built-in strategies, or provide her own custom filter policy.
2. Frame Redundancy Filtering using SSIM
To avoid processing nearly identical consecutive frames, such as when the drone is hovering or the scene is visually unchanged, we use the Structural Similarity Index Measure (SSIM) to compare each sampled frame with the one immediately before it.
- If the SSIM score is high, indicating minimal visual change, the frame is discarded.
- If the score is below a defined threshold, the frame is passed to the next stage.
This step removes low-value frames that add little new visual information, ensuring that the pipeline focuses on capturing temporal or visual variation rather than static redundancy.
3. Uncertainty-Based Filtering using a Pretrained Object Detector
Each retained frame is analyzed by a general-purpose object detection model, such as YOLOv8n. The model provides both class predictions and associated confidence scores.
To prioritize frames where the model is uncertain, we compute an uncertainty score based on prediction confidences. If the uncertainty exceeds a given threshold, the frame is considered valuable for training and proceeds to the next stage.
This step targets the model’s blind spots, ensuring that collected data helps reduce prediction uncertainty over time.
4. Diversity Filtering with Embedding Similarity
Even if a frame passes the redundancy and uncertainty filters, it may still be visually similar to previously collected frames. To avoid this, we extract intermediate feature embeddings from the backbone of the detection model and compare them to embeddings of already saved frames using cosine similarity.
If the similarity to existing embeddings is below a certain threshold, the frame is considered sufficiently diverse and is saved. Otherwise, it is discarded.
This encourages the dataset to cover a wide variety of visual conditions and object appearances.
5. Local Storage and Labeling
Frames that pass all previous filters are saved locally on the edge device. These images can then be labeled using a tool such as Label Studio, which can be deployed offline to maintain data privacy.
6. Integration with Federated Learning
Once labeled, the data is used in a new training round within a federated learning system powered by Scaleout Edge. Rather than uploading the raw data, the device trains a local model and shares only the model updates with a central aggregator. This preserves privacy while allowing the global model to benefit from new data collected at the edge.

Why This Matters
This edge-first data selection approach brings several key advantages:
- Efficiency: Only the most informative frames are annotated and trained.
- Privacy: Raw video remains strictly on the device.
- Adaptivity: The system prioritizes uncertain and diverse samples, ensuring continual model improvement.
- Scalability: Works seamlessly across fleets of drones, sensors, or edge devices.
- Customizability: Each use-case can tune thresholds, filters, and models to fit its unique data stream.
Summary
Data selection on the edge allows for adaptive federated machine learning using Scaleout Edge. Instead of sending raw streams to a server, devices filter, label, and train on only the most valuable data locally, contributing model updates that make the global model stronger while data stays private.
This approach is part of VisionKit, our development kit for federated computer vision. VisionKit provides supervised and self-supervised model options, active data selection strategies, and a direct integration with Scaleout Edge.
If you are exploring privacy-preserving, adaptive AI systems for the edge, we’d love to collaborate. Learn more about use-cases for VisionKit.
Author David Hovstadius, Machine Learning Engineer