Table of Contents
Federated Machine Learning (FedML) has emerged as a promising approach to machine learning that addresses data privacy concerns by enabling model training across distributed data sources without sharing the raw data. This paradigm is particularly valuable in data-sensitive domains like healthcare, finance, and telecommunications, where privacy regulations and competitive concerns often prevent data sharing.
The paper "Scalable Federated Machine Learning with FEDn" introduces a novel framework designed to bridge the gap between theoretical federated learning algorithms and their practical implementation in real-world, geographically distributed environments. Unlike many existing frameworks that focus primarily on algorithmic aspects or simulated environments, FEDn prioritizes scalability, robustness, and production-readiness.

Figure 1: The three-tier architecture of FEDn, showing the relationship between clients, combiners, and the controller. The design allows for horizontal scaling by adding more combiners to handle increased client loads.
Federated learning allows multiple participants (clients) to collaboratively train machine learning models while keeping their data local. This approach addresses key privacy concerns but introduces significant technical challenges:
Federated learning scenarios typically fall into two categories:
Existing frameworks like TensorFlow Federated (TFF), PySyft, FATE, and PaddleFL each have their strengths but often lack the combination of scalability, framework-agnosticism, and production-readiness needed for widespread adoption in complex real-world deployments.
FEDn employs a three-tier architecture inspired by the map-reduce paradigm, consisting of:

Figure 2: Detailed software architecture of FEDn showing the components of each tier and the communication protocols between them.
The hierarchical structure allows the system to scale horizontally by adding more combiners as the number of clients increases. This design is particularly valuable for handling geographically distributed clients, as combiners can be strategically placed closer to client clusters to minimize latency.
Communication between clients and combiners uses Google Remote Procedure Call (gRPC) with Protocol Buffers, providing high performance and language flexibility. The combiners and controller use both gRPC and REST APIs for different types of interactions.
Several core principles differentiate FEDn from other federated learning frameworks:
The combiners in FEDn are designed to be stateless, with all persistent state managed by the controller and its associated database (MongoDB). This design choice:
FEDn adopts a black-box execution model that allows clients to use any machine learning framework (TensorFlow, PyTorch, scikit-learn, etc.) as long as they can serialize and deserialize model updates. This flexibility is crucial for heterogeneous environments where clients may have different technical requirements or preferences.

FEDn introduces the concept of a "compute package" - a collection of code that defines how clients perform local training and model evaluation. This allows complete flexibility in the federated learning algorithm while maintaining a consistent interface for the FEDn system.
While the framework does not directly implement privacy-enhancing technologies like differential privacy or secure aggregation, its architecture is designed to support these additions. The combiner network provides natural points for implementing secure aggregation protocols.
The authors evaluated FEDn using two real-world use cases:
A natural language processing (NLP) task using BERT models ranging in size from 10MB to 1GB. This scenario tested the system's ability to handle large models in a cross-silo setting with relatively few clients but significant computational demands.

Figure 3: Training accuracy comparison between federated learning with different numbers of clients (2, 5, and 10) versus centralized training. As more clients participate, federated accuracy approaches centralized performance.
A human activity recognition task using smartphone sensor data, designed to test the system's ability to handle many resource-constrained clients. Experiments were conducted with up to 1,000 simulated clients.
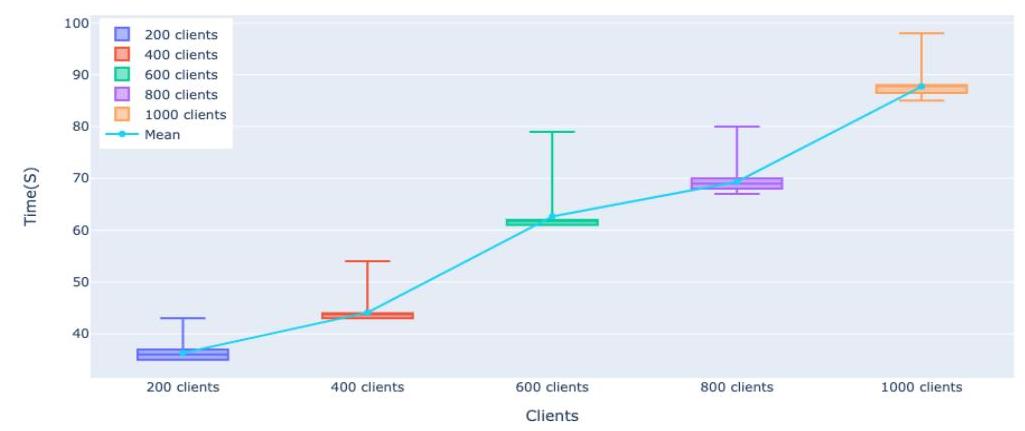
4: Round times as the number of clients scales from 200 to 1,000. The linear increase demonstrates FEDn's scalability even with large numbers of clients.
The experiments revealed several key insights about FEDn's performance characteristics:
As model size increases, both client training time and combiner round time increase, but adding more combiners can significantly reduce round times for large models.

Figure 5: Impact of model size on client training time and combiner round time. The rightmost two columns show how adding more combiners (2CB and 4CB) can reduce round times for 200MB models.
The authors conducted experiments with geographically distributed clients and combiners across multiple AWS regions in Europe and the United States, demonstrating the framework's effectiveness in realistic, distributed settings.

Figure 6: (A) Geographic distribution of clients and combiners across AWS regions. (B) Performance comparison with different combinations of combiners (CB) and clients (CL) in a geographically distributed setting.
A detailed breakdown of combiner operations reveals that most of the time (57.5%) is spent waiting for client updates, with model loading (19.2%) and fetching (14.1%) being the next most time-consuming operations.

Figure 7: Breakdown of combiner operations, showing that waiting for client updates dominates the time spent during a round.
The framework efficiently distributes workload across different tiers, with clients handling most of the computational load while combiners manage coordination and aggregation with relatively modest resource requirements.

Figure 8: Left: Workload distribution between combiners, clients, and communication for different resource configurations. Right: Runtime distribution and resource utilization for 600 clients.
FEDn offers several advantages over existing federated learning frameworks:
The FEDn framework opens up several promising directions for future research and application:
The FEDn framework represents a significant advancement in making federated learning practical for real-world deployment. By focusing on scalability, robustness, and framework agnosticism, it addresses critical gaps in the existing federated learning ecosystem.
The experimental results demonstrate that FEDn can effectively handle both cross-silo scenarios with large models and cross-device scenarios with many clients. The architecture's scalability through horizontal combiner expansion provides a clear path for handling even larger federated learning applications.
As privacy concerns continue to grow and data regulations become more stringent, frameworks like FEDn will play an increasingly important role in enabling collaborative machine learning without compromising data privacy. The open-source nature of the framework also encourages further research and development in this rapidly evolving field.
Brendan McMahan, Eider Moore, Daniel Ramage, Seth Hampson, and Blaise Aguera y Arcas. Communication-efficient learning of deep networks from decentralized data. InArtificial Intelligence and Statistics, pages 1273–1282, 2017.
Peter Kairouz, H Brendan McMahan, Brendan Avent, Aurélien Bellet, Mehdi Bennis, Arjun Nitin Bhagoji, Keith Bonawitz, Zachary Charles, Graham Cormode, Rachel Cummings, et al. Advances and open problems in federated learning.arXiv preprint arXiv:1912.04977, 2019.
Keith Bonawitz, Hubert Eichner, Wolfgang Grieskamp, Dzmitry Huba, Alex Ingerman, Vladimir Ivanov, Chloe Kiddon, Jakub Konecny, Stefano Mazzocchi, H Brendan McMahan, et al. Towards federated learning at scale: System design. arXiv preprint arXiv:1902.01046, 2019.
Jakub Koneˇcný, H. Brendan McMahan, Felix X. Yu, Peter Richtarik, Ananda Theertha Suresh, and Dave Bacon. Federated learning: Strategies for improving communication efficiency. InNIPS Workshop on Private Multi-Party Machine Learning, 2016.
Read full paper on Arxiv here
%201.svg)