We are releasing a new toolkit aimed to support large-scale development of cross-device federated learning applications. In this post we demonstrate cost-effective simulations of 10 000 intermittently connected clients, each dropping out and reconnecting at random intervals. To achieve this level of scalability we deployed eight combiners together with a single reducer. After 100 rounds of training we terminated the run, having verified stable convergence.
Edge devices such as factory PLCs, trucks, drones, and mobile phones generate large volumes of data useful for machine learning. However, much of this data is too sensitive to send to the cloud because of privacy concerns, network bandwidth cost and real-time constraints that restrict standard centralized workflows.
Federated learning unlocks these siloed datasets by training where the data resides, however it is a challenge to scale federated learning to hundreds of thousands of asynchronous clients. By releasing a cross-device simulation toolkit, and by demonstrating that Scaleout Edge can effectively handle large numbers of clients, it is our hope to accelerate development of privacy-preserving alternatives for large scale AI.
In this blog post we show a reference deployment, consisting of eight combiners and a single reducer supporting 10 000 asynchronous clients training for 100 rounds.Finally we show that Scaleout Edge can keep a global model converging while raw data never leave the device, shrinking the attack surface and increasing data privacy.
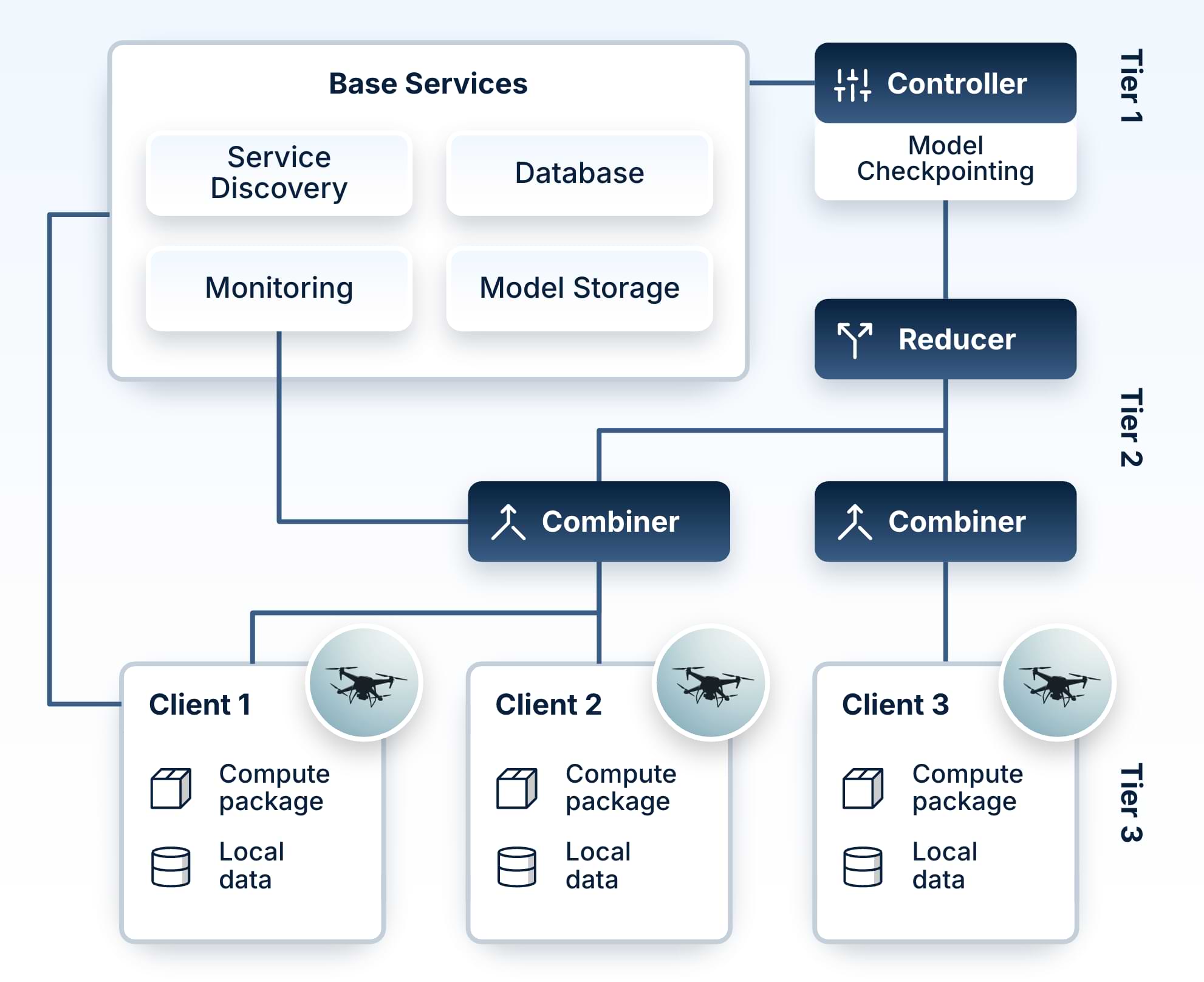
The Scaleout Edge architecture follows a three-tier design
Tier 1 consists of the clients, anything from drones, trucks to smartphones, factory PLCs, or hospital servers, each training on local data (which never leaves the clients) and producing a model update for the current round. The client side SDKs are the main entry point for developers – they specify machine learning code for computing model updates, integrate with their own application (as needed) and specify model validation and telemetry routines. THey also have the possibility to specify custom server-side model aggregation schemes. Client-side SDKs are available in Python3, C++ and Kotlin.
Tier 2 consists of combiner/s and a reducer. Every client is assigned to a single combiner. During each round each combiner waits until it has received all of its clients’ updates, or until the round timeout elapses. It then proceeds to aggregate its updates into a partial model. When every combiner has produced its partial model (or the round timeout is reached), the reducer merges the partial models into a new global model. That global model is then sent to the clients for validation, and the process is iterated until the desired number of rounds have been executed.
Tier 3 houses the control plane. The controller orchestrates each training round, tracks the lineage of global models, and maintains a global state. Alongside it, a discovery service detects inbound client connections and routes each new client to an available combiner. Tier 3 implements the logic for handling client re-assignment after dropouts.
Scaleout Edge is built for fault tolerance and scalability
The three-tier architecture makes horizontal scaling straightforward. When we ramped up to 10 000 clients, we simply deployed eight combiners and the system could easily absorb the increased load. Because the combiners never speak to one another and are solely responsible for its designated clients, Scaleout Edge provides a high fault-tolerance – an unresponsive combiner only affects its respective clients and the remaining combiners can continue to aggregate their partial models, which allows the reducer to produce a new global model and keep the training session moving forward. If an unresponsive combiner fails to come alive after a configurable time interval, its clients are automatically assigned to another combiner.
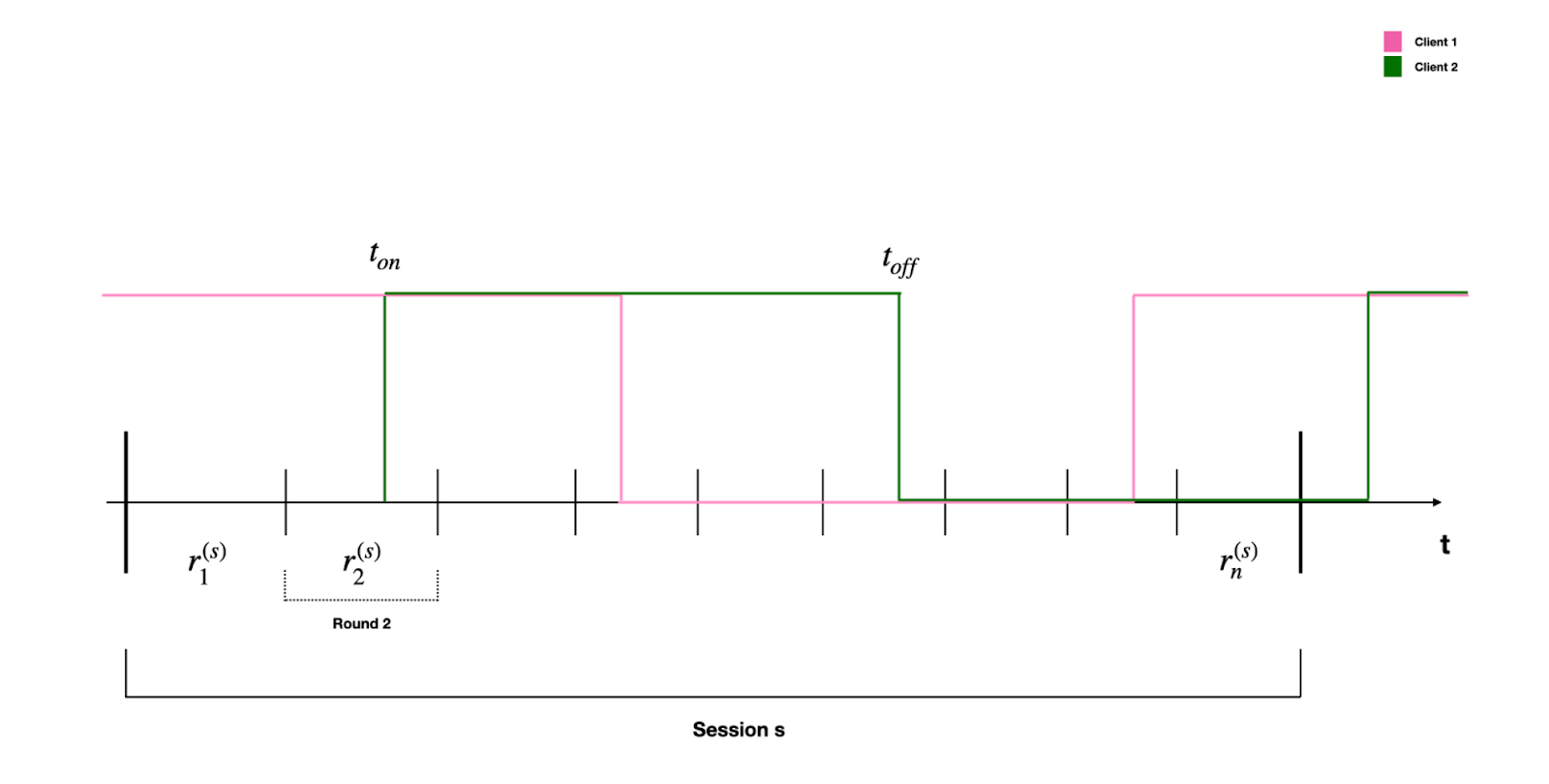
To simulate intermittent connectivity, a common reality in edge AI and cross-device federated learning, we developed an asynchronous script that connects N clients with a 1 second delay between each client connecting to Scaleout Edge Studio. The script was launched from 12 Virtual Machines of varying sizes. Each client stayed online for 2 minutes until disconnecting and sleeping for a random interval between [1, 30] seconds. After launching the client script we then upload the seed model, which is the first model of the training session, and which is distributed to the clients at the start of the session for local training. The initial delay of 1 second between each new client connection and the random sleep interval between [1, 30] seconds, causes the clients to drop in and out of training asynchronously and thus produces a realistic federated learning testbed in a cross-device setting.
The session is launched through the experiment script (run_experiment.py), which sets the round timeout to 90 s, deliberately shorter than the clients’ 120 s online window. This design creates what we call stragglers– clients that finish training after the controller has already advanced to the next round, and therefore upload updates based on an out-of-date global model. Handling these late contributions is a real-world challenge in production federated learning and something that we will take a hard look at in a future post.


Figure 3 charts test accuracy across 100 federated rounds with 10 000 clients, each online for 120 s (ton) then offline for 1–30 s (toff), with a round timeout of 90 s. In this churn-heavy scenario the test accuracy curve follows the expected shape, climbs sharply initially and then plateau in the late rounds. The absence of noticeable dips shows that Scaleout Edge three-tier architecture (clients → combiners → reducer) is both able to absorb stragglers without harming global model convergence and underlines the framework’s fault-tolerance and scalability when faced with a significant load of asynchronous federated clients.
Scaleout Edge Topology at 10 000 Clients

Hardware reference
The client virtual machines do not host any of Scaleout Edge server functionalities, but were solely deployed to enable the level of concurrency needed to scale 10 000 asynchronous clients. Make sure to raise the ulimit for each VM, due to the number of threads active on each VM.
Lessons Learned
Note that to scale to 10k clients, you need a dedicated deployment of Scaleout Edge – reach out to the Scaleout team if you are doing research in cross-device FL to discuss arranging a scaled testbed for your research needs.
This work was funded by Vinnova.
%201.svg)