Autonomous vehicles generate a massive amount of data from sensors like cameras, LiDAR, and radar. This data can be highly valuable for AI development as it contains information about day-to-day interactions in traffic. Specifically, image data can be used to train foundational computer vision models that can then be used to solve problems in autonomous driving.
However, there are fundamental challenges to scale up machine learning in vehicle fleets:
- Data Privacy. As vehicles collect detailed information about their environments, ensuring that this data is handled in a way that respects privacy laws and norms is crucial.
- Regulatory Compliance. Adhering to evolving regulatory standards related to data use, storage, and sharing in different jurisdictions can be complex.
- Data volume and velocity. Autonomous vehicles generate a massive amount of data from sensors like cameras, LiDAR, and radar. Managing and processing this sheer volume of data in real-time or near-real-time is a significant challenge.
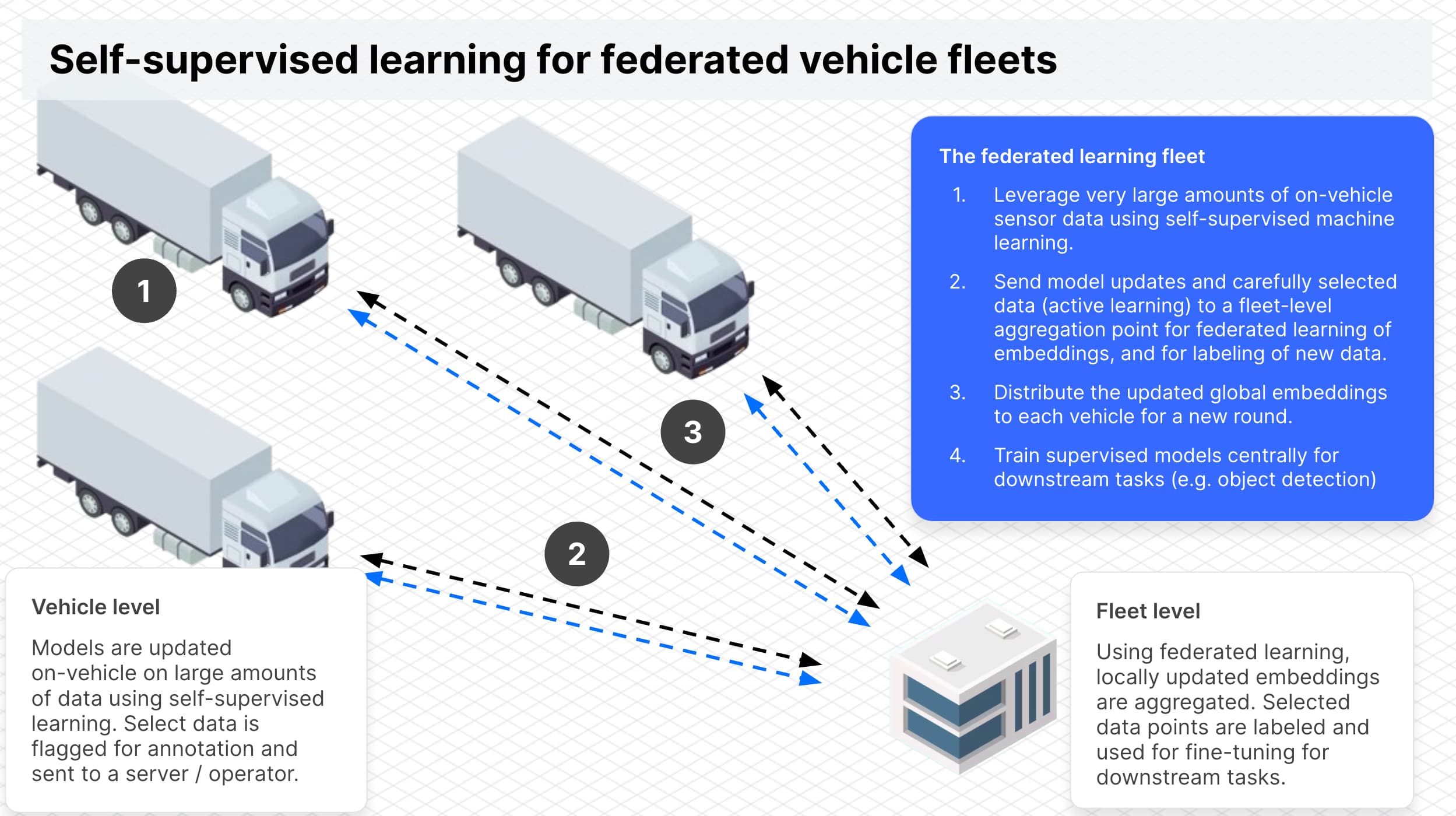
A vision for the federated vehicle fleet. Multiple vehicles collaborate using federated learning to leverage large amounts of unlabeled data to train robust embeddings. With semi-supervised and active-learning, these embeddings are then used to fine tune for downstream tasks such as object detection.
Federated learning (FL) provides a solution for dealing with constrained bandwidth and sensitive data by keeping the data at its source (on-vehicle) and computing updates to a ML model at the edge, instead of transferring the data to a centralized storage. By aggregating such model updates from a large number of vehicles, FL holds the promise to enable real-time learning across vehicle fleets.
Learning (almost) without labels
Most computer vision algorithms in autonomous driving require labels, but the vast amounts of data collected on the edge cannot possibly be labeled. So how can we make use of all this generated data?
Self-supervised learning has become an increasingly popular approach in computer vision, as it can use the large amount of available, yet unlabeled data. By combining both federated learning and self-supervised learning (referred to as “federated self-supervised learning”), one can utilize on-vehicle data, without transferring or labeling the data.
In this blog post, we will first provide an overview over self-supervised learning, followed by a more detailed explanation of a popular self-supervised learning framework called SimSiam. Finally, I will show how one can apply SimSiam in a federated learning setup (FedSimSiam), and showcase how it can solve computer vision problems for autonomous driving.
Self-supervised Learning
Self-supervised learning is a relatively new approach in machine learning that does not require labeled data. Instead, the goal of self-supervised learning is to learn an encoder f that captures meaningful representations of unlabeled image data. After training the encoder on a large amount of data, it is fine-tuned on a task of interest, a so-called “downstream-task”. This could be for example image classification, object detection, or a segmentation task. Fine-tuning is performed using supervised learning. However, since the encoder already learned useful features for the downstream task during self-supervised training, only a small labeled dataset is now required to achieve a high accuracy. The figure below visualizes a common workflow of self-supervised learning.
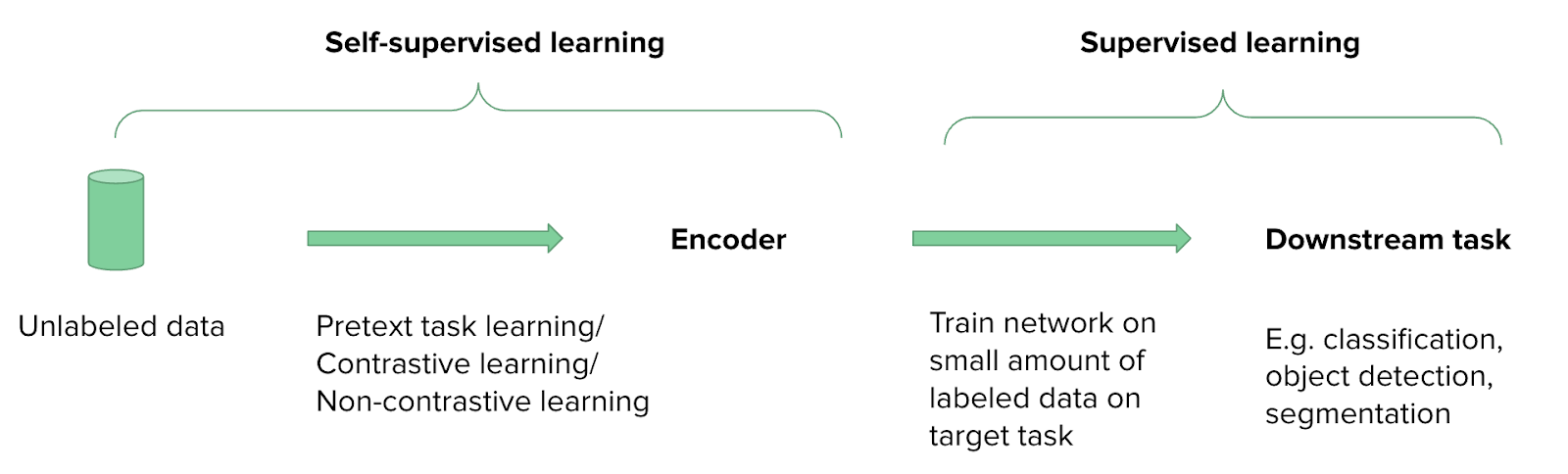
How exactly does self-supervised learning work? Self-supervised learning is an unsupervised learning method as it is applied to unlabeled data. However, it uses supervised learning principles by implicitly generating labels. The labels are derived from the data itself by either applying transformations on the data, or by hiding parts of the data. A model is then trained to predict the hidden parts, making it a supervised learning problem even though there is no external source providing the labels. Self-supervised methods can be categorized in three groups: Pretext task learning, contrastive learning, and non-contrastive learning.
In pretext task learning, the model has to solve a task which enforces a good “semantic”
understanding of the underlying structure of the data. A common task is rotation prediction [1]: An image is rotated by random multiples of 90 degrees (e.g., 0, 90, 180, or 270 degrees). The model then has to predict the degree of rotation that was applied. This is a 4-class classification problem. To predict the correct rotation, the model has to be aware of the semantic concepts depicted in the images. For instance, it must understand that the feet of an animal are typically positioned at the bottom of an image.
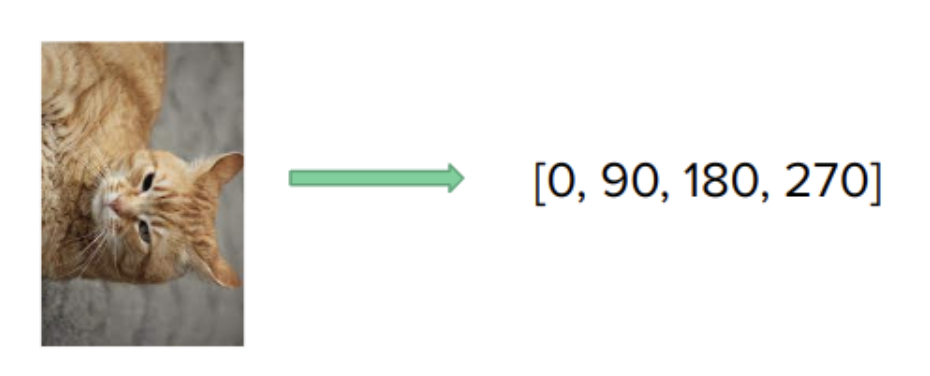
There exist a variety of different pretext tasks that one can use. However, they are relatively hand engineered and there is no guarantee that the model is actually learning useful features for the downstream task, which is why they are a bit outdated.
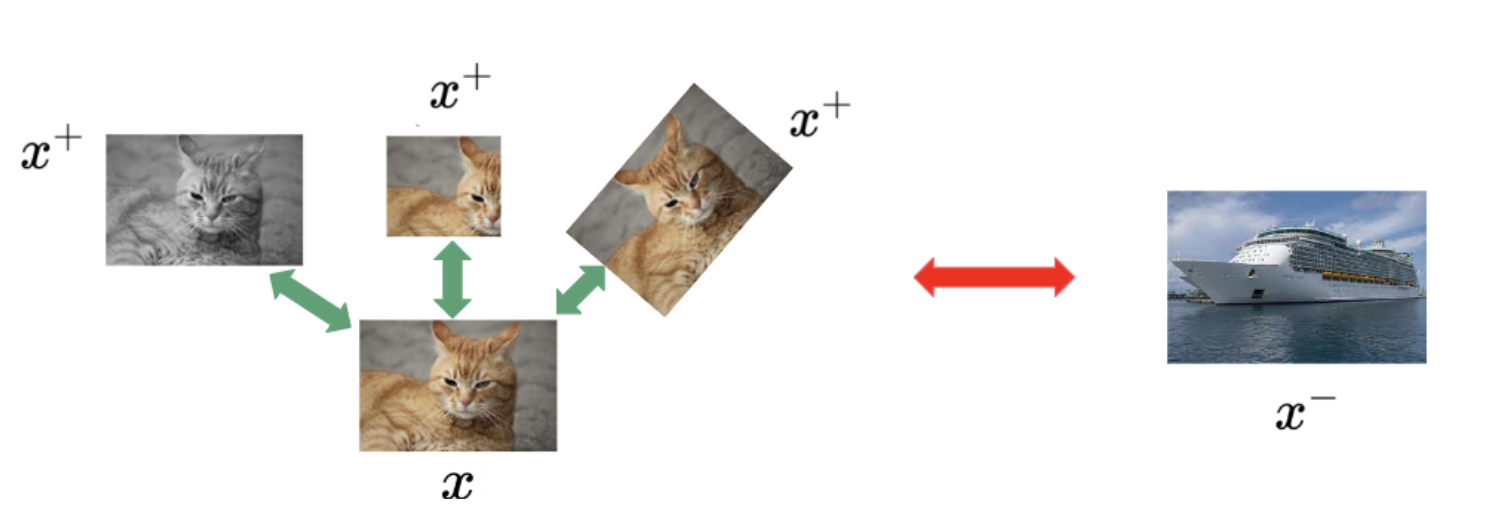
Contrastive learning was developed toprovide a more theoretical foundation for self-supervised learning. In contrastive learning, the original input image is denoted as reference image x. Augmentations of the reference image are referred to as positive views x+ and different images as negative views x−. The figure below visualizes the contrastive learning setting. For a given scoring function s, an encoder f is trained that should yield a high score for a positive pair (x, x+) and a low score for a negative pair (x, x−). By minimizing the so-called InfoNCE loss, the distance in the embedding space between positive pairs (x, x+) is minimized, while the distance between negative pairs (x, x-) is maximized. Two popular frameworks for contrastive learning are SimCLR [2] and MoCo [3].
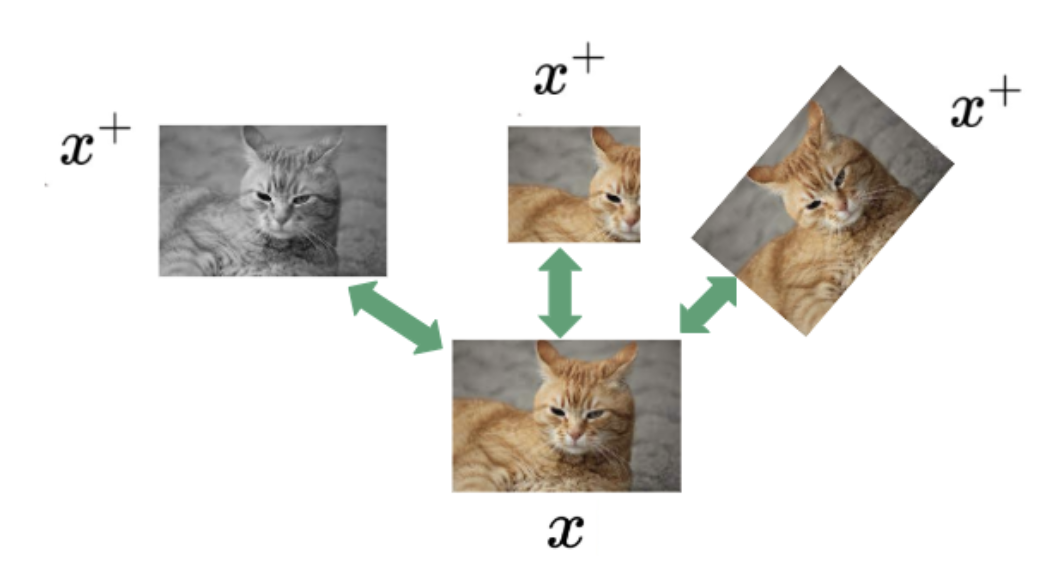
Unlike contrastive learning, non-contrastive learning only uses positive views x+ of a reference image x, and no negative views x−. The objective is to maximize the similarity between the feature embeddings of positive pairs. The figure below visualizes the non-contrastive learning setting. By only minimizing the distance in the embedding space, it is likely that all input images are mapped to the same feature embedding, as this will always minimize the loss function. In that case, the loss would be zero. The collapse into a constant solution is referred to as representational collapse in literature [4].
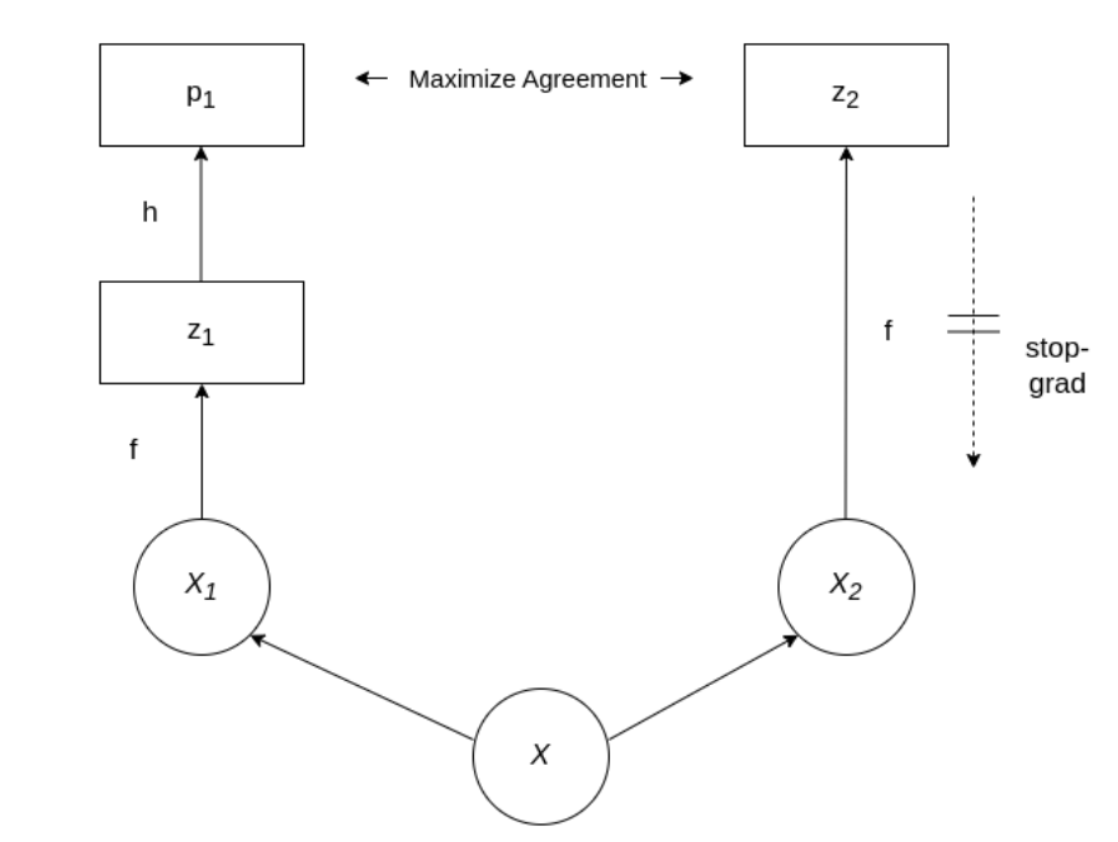
SimSiam
A popular framework in non-contrastive learning is SimSiam [5]. SimSiam generates two augmentations (called ‘views’) x1 and x2 of an input image x. Both views are input to the same encoder network f, consisting of a ResNet backbone. From the resulting output vectors z1 and z2, only z1 is input to a prediction network h, which produces the output vector p1. The objective in SimSiam is to maximize the agreement between p1 and z2. To prevent representational collapse, the gradient is back-propagated only on the side of the prediction network. SimSiam’s architecture is relatively simple, while still achieving state-of-the-art results in various downstream tasks.
Federated Self-supervised Learning with FedSimSiam
Remember our initial problem: Cameras of modern vehicles collect large amounts of valuable data, however, they cannot be stored or transferred to a centralized storage due to constrained bandwidth and privacy reasons. Federated learning provides a solution for dealing with this problem by moving the model to the data. This is great, but it is impossible to label the generated data on-vehicle. Since self-supervised learning does not require labels, we can overcome this issue. Combining federated learning and self-supervised learning (federated self-supervised learning) provides a way to learn useful representations on-vehicle, without the need to transfer or label the data.
FedSimSiam is simply the federated version of SimSiam, where server-side aggregation is done using federated averaging (FedAvg). Applying SimSiam in a federated setting comes with new challenges, such as data heterogeneity, but in this blog post we will not dive into that. Instead, let’s focus on how one could use FedSimSiam in autonomous driving challenges. The Zenseact Open Dataset (ZOD) [6] is a multi-modal autonomous driving dataset that contains real-world traffic data captured by driving vehicles. In my Master’s thesis, I split unlabeled image data of the ZOD across multiple clients (which in this case represent different vehicles that collected that data) and trained FedSimsiam on it to learn useful representations of real-life traffic scenarios. Afterwards, I fine-tuned the trained encoder on a relatively small number of labeled data to detect cars. The figure below visualizes the workflow.
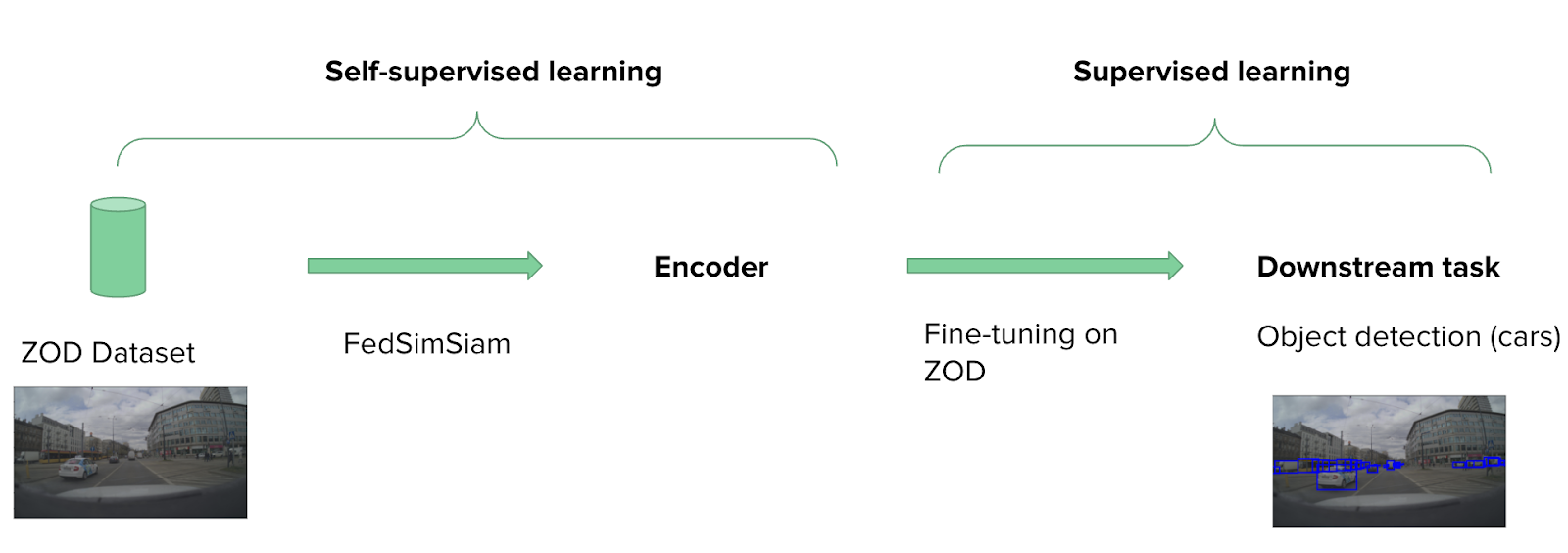
The fine-tuned model can then be used to detect cars on new, unseen data as shown in the picture below. This is an example of how federated self-supervised learning can be used to enhance autonomous driving by using data generated on the edge by modern vehicles. It is a new, but highly active and promising area of research. Many new, more advanced algorithms are being developed to specifically address the challenges in autonomous driving. Keep an eye out for future publications in this field.

Run FedSimSiam in FEDn
You can now run FedSimSiam yourself in FEDn by following the steps described here:
https://github.com/scaleoutsystems/fedn/tree/master/examples/FedSimSiam
In this example we train FedSimSiam on the CIFAR-10 dataset, which is split across 2 clients.
FEDn is our federated learning framework that enables seamless development and deployment of federated learning applications. Learn more about FEDn here:
https://www.scaleoutsystems.com/framework.
CIFAR-10 is a popular benchmark dataset that contains images of 10 different classes, such as cars, dogs, and ships. After the self-supervised training stage, the resulting encoder can be trained for image classification via supervised learning on labeled data. Even training with a small subset of labeled CIFAR-10 data achieves high classification accuracy.
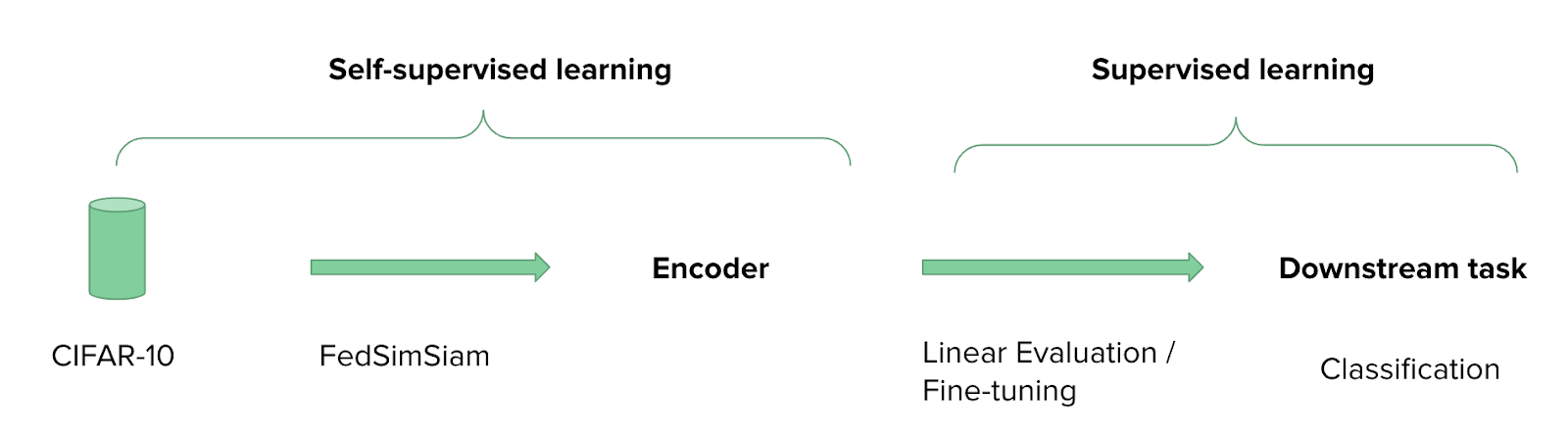
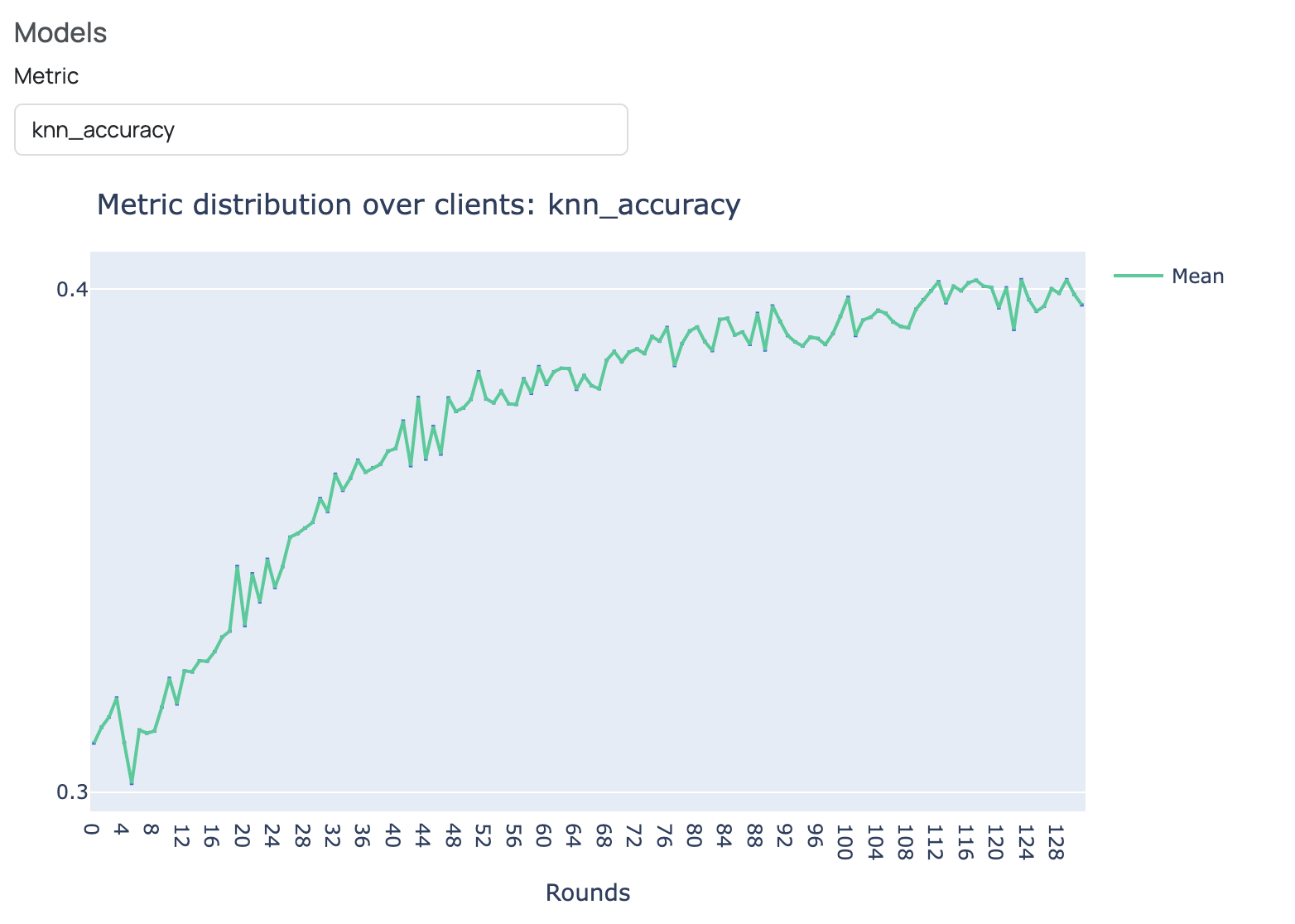
When running the example in FEDn Studio, the training progress of FedSimSiam is monitored using a kNN classifier. After each training round, a kNN classifier is fitted to the feature embeddings of the training images obtained by FedSimSiam's encoder and evaluated on the feature embeddings of the test images.
This is a common method to track FedSimSiam's training progress, as FedSimSiam aims to minimize the distance between the embeddings of similar images. If training progresses as intended, accuracy increases as the feature embeddings for images within the same class are getting closer to each other in the embedding space. Below is a screenshot of the kNN monitoring in FEDn Studio after 128 training rounds. We can see that the kNN accuracy increases over the training rounds, indicating that the training of FedSimSiam is proceeding as intended.
When the training of FedSimSiam is finished, the final model can be downloaded and trained on a downstream task. Go try it yourself!
If you have any questions regarding the example or FEDn, feel free to contact me at jonas@scaleoutsystems.com.
References:
[1] Gidaris, Spyros, Singh, Praveer, and Komodakis, Nikos. “Unsupervised Representation Learning by Predicting Image Rotations”. In: ICLR (2018).
[2] Chen, Ting, Kornblith, Simon, Norouzi, Mohammad, and Hinton, Geoffrey. “A Simple Framework for Contrastive Learning of Visual Representations''. In: Proceedings of the 37th International Conference on Machine Learning. ICML’20. JMLR.org, 2020.
[3] He, Kaiming, Fan, Haoqi, Wu, Yuxin, Xie, Saining, and Girshick, Ross. “Momentum Contrast for Unsupervised Visual Representation Learning”. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2020, pp. 9726–9735. doi: 10.1109/CVPR42600.2020.00975.
[4] Jing, Li, Vincent, Pascal, LeCun, Yann, and Tian, Yuandong. “Understanding Dimensional Collapse in Contrastive Self-supervised Learning”. In: International Conference on Learning Representations. 2022.
[5] Chen, Xinlei and He, Kaiming. “Exploring Simple Siamese Representation Learning”. In: 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). 2021, pp. 15745–15753. doi: 10.1109/CVPR46437.2021.01549.
[6] Alibeigi, M., Ljungbergh, W., Tonderski, A., Hess, G., Lilja, A., Lindstrom, C., Motorniuk, D., Fu, J., Widahl, J., & Petersson, C. (2023). Zenseact Open Dataset: A large-scale and diverse multimodal dataset for autonomous driving. In: Proceedings of the IEEE/CVF International Conference on Computer Vision.