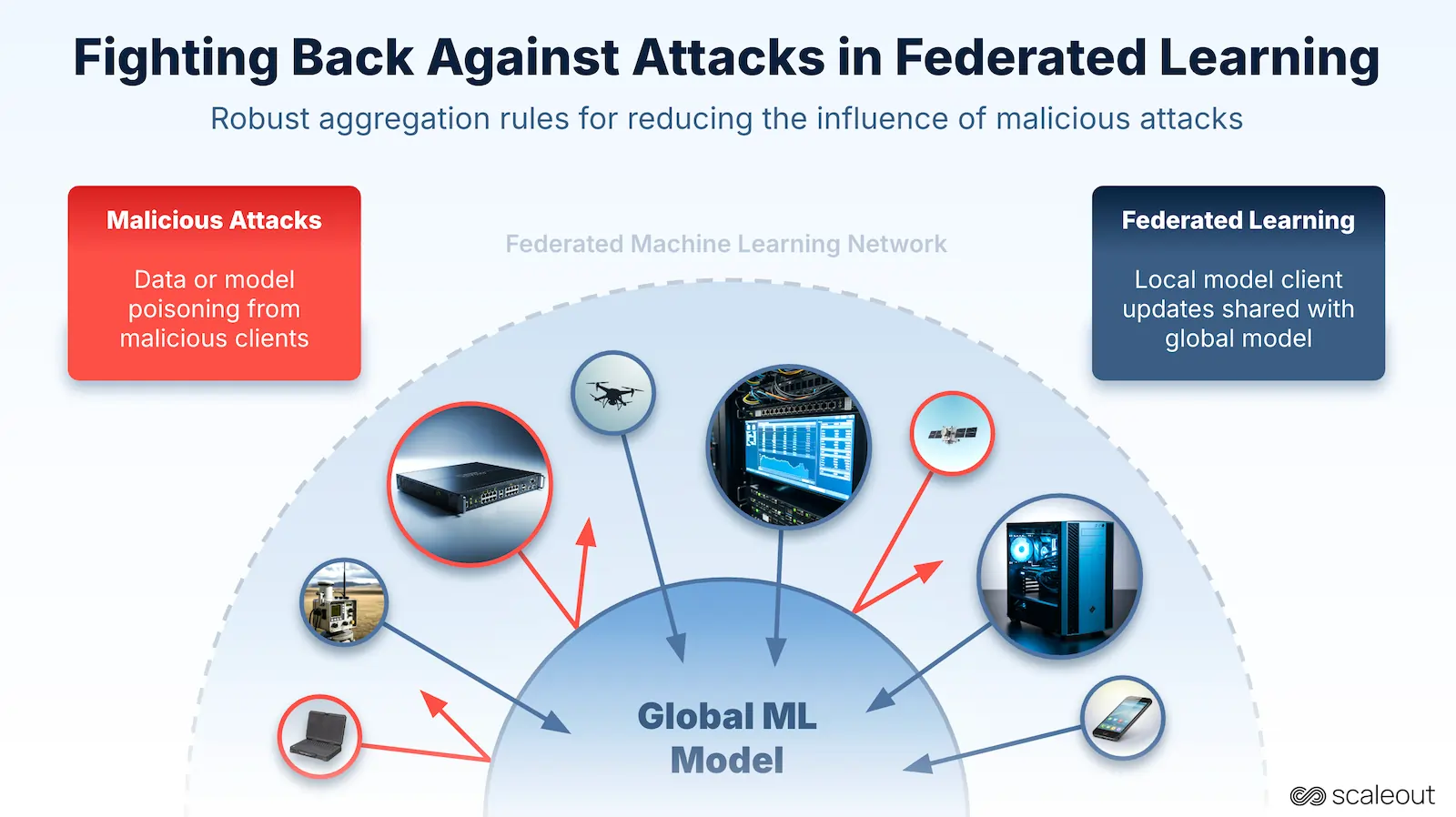
Federated Learning (FL) is reshaping how AI models are trained. Instead of gathering data in one central place, each device trains locally and only shares model updates. This approach protects privacy and allows AI to run closer to where data is generated.
But spreading computation and data across many devices also opens the door to new threats. Malicious participants can influence training by manipulating their contributions, leading to biased results, hidden backdoors, or performance degradation.
In FL, these threats often appear as:
These attacks are especially tricky when the data across clients is non-IID, imbalanced, or when attackers join the training process late, scenarios that reflect real-world federations. Common defences like Multi-KRUM, Trimmed Mean, or Divide and Conquer help, but they can fail under these complex conditions.
To investigate defences, we developed a multi-node attack simulator built on the FEDn framework. It allows scaled, reproducible testing of different attack and defence strategies with hundreds or even thousands of simulated clients.
Key capabilities include:
The simulator is open-source and available for testing by both researchers and industry.
The study compared several aggregation rules:
Across 180 experiments, results highlighted that static aggregation rules were often insufficient. In heterogeneous or imbalanced client setups, malicious updates could slip through, especially if attackers joined later in training.
EE-TrMean, however, adapted dynamically, scoring clients based on past reliability, selectively excluding low-quality updates, and occasionally re-testing others. This allowed it to reduce the impact of adversaries while keeping the model stable and accurate.
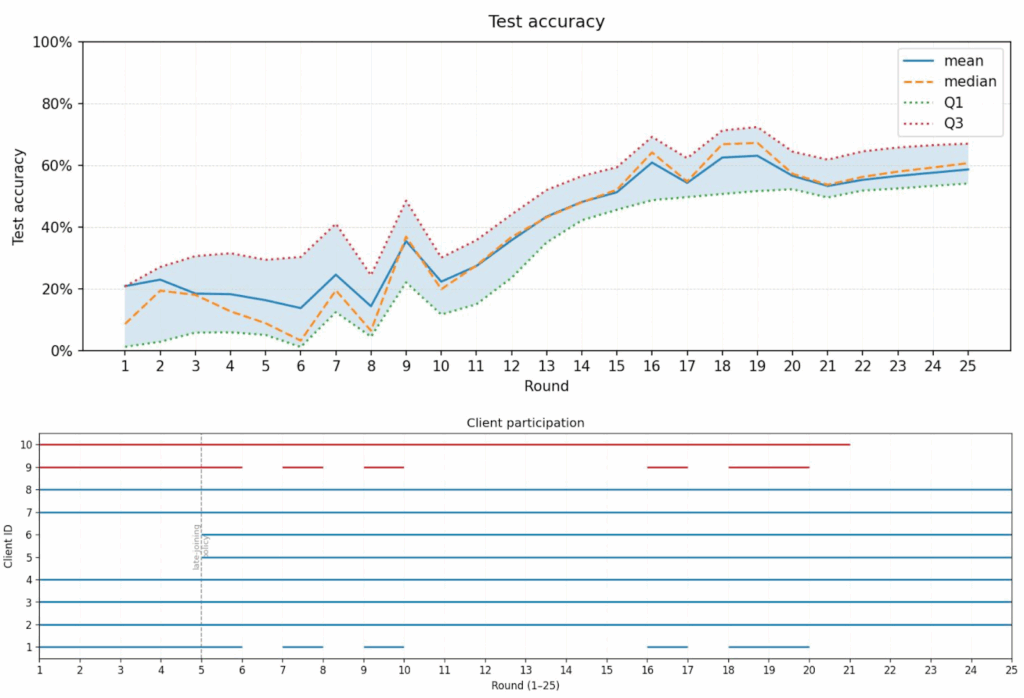
FL systems are complex, with clients joining and exiting, and data rarely being uniform. Static rules fail to account for this fluid reality. Adaptive strategies like EE-TrMean provide resilience not only to intended attacks but also to unintentional disruptions from faulty devices or misconfigured clients.
As federated learning scales to fleets of devices and real-world deployments, building adaptive defences becomes critical. Tools like the multi-node simulator and strategies such as EE-TrMean is a step toward more secure, attack-resilient FL systems.
This article by Salman Toor and Sigvard Dackevall is an excerpt from the post "Fighting Back Against Attacks in Federated Learning" published on Towards Data Science.
%201.svg)