Federated learning (FL) has emerged as a powerful approach to training machine learning models in a privacy-friendly manner by keeping data on users' devices and sharing only model updates. This decentralized method reduces the risks associated with transferring sensitive data to a central server, making it an appealing solution for Collaborative AI (e.g. in healthcare, finance), and fleet learning (e.g. with smart devices, vehicles).
Although federated learning inherently enhances data privacy by design, there is still room to further strengthen protection. Model updates can sometimes reveal subtle information about individual data points, particularly when dealing with small or unbalanced datasets. This is where differential privacy (DP) plays a crucial role. By introducing carefully calibrated noise into the training process, differential privacy ensures that individual contributions remain unidentifiable while still enabling the model to learn valuable patterns.
Differential Privacy
Differential Privacy (DP) provides a privacy-preserving guarantee for a mechanism $M$ that operates on a dataset $D$.
The original $\epsilon$ -DP expression reads:
$$ \begin{equation} P[M(D)\in X] \leq e^\epsilon P[M(D')\in X], \quad \forall D' \quad [1] \end{equation} $$
where $D'$ represents any dataset differing from $D$ by a single data point. Eq. 1 states that for any output $X$, the probability that the mechanism $M$ produces an output within $X$ when acting on $D$ is at most $e^\epsilon$ times the probability of producing the same output when acting on $D'$. This definition ensures that the output distribution of the mechanism does not change significantly whether any single individual's data is included or excluded from the dataset, thereby providing a formal privacy guarantee. The parameter $\epsilon$ controls the privacy level, with smaller values indicating stronger privacy guarantees.
An updated version of this is the $(\epsilon, \delta)$ -Differential privacy:
$$ \begin{equation} P[M(D)\in X] \leq e^\epsilon P[M(D') \in X] + \delta, \quad \forall D' \quad [2] \end{equation} $$
, indicating that Eq. [1] holds with probability $1-\delta$. The term $\delta$ is typically very small, allowing for greater flexibility in defining DP processes.
Let us start with a simple example to better understand the utility of DP protected mechanisms.
The example is based on a gaussian mechanism to keep the query DP secure. The choice of noise mechanism for our example does not necessarily give the tightest bound nor is it the simplest choice to explain, but it is related to how DP is used in DP-SGD.
Example: An (ϵ,δ)-protected database query
Assume there is a semi-private database $D$ holding some personal feature $f$, for a set of users. You are allowed to query the average of $f$ from $D$, but nothing else. You perform an average $f$ query at time $t_0$ and obtain the result $M(D_{t_0})$. At a later time $t_1$, you suspect that a new user has entered the database. To confirm this, you could query the average $M(D_{t_1})$ again. If the output has changed, it indicates that the database has been modified. If you know that it is highly unlikely that anyone else entered or exited $D$ in the time frame $[t_0, t_1]$, then you might suspect that the specific user has indeed entered $D$, and you could compute the value of the new user's feature:
$$ \begin{equation} f_{\text{new}} = (n + 1)M(D_{t_1}) - nM(D_{t_0}) \end{equation} $$
where $n$ is the number of users in the database at time $t_0$.
To protect against this kind of inference, the query mechanism can be made $(\epsilon,\delta)$ -differentially private by clipping extreme values and adding Gaussian noise to the query response. The protected query mechanism can be defined as:
$$ \begin{equation} M(D)_{(\epsilon,\delta)} = M(D)_{\text{clip}} + N(0,\sigma^2) \end{equation} $$
Where:
- $M(D)_{\text{clip}} = \frac{1}{|D|} \sum_{i=1}^{|D|} \text{clip}(f_i, C)$
- $\text{clip}(f_i, C) = \min(1, \frac{C}{|f_i|}) \cdot f_i$ ensures that the magnitude of fi does not exceed a predefined clipping value C.
- $N(0, \sigma^2)$ is Gaussian noise added to ensure privacy.
Now, our query mechanism outputs values from a Gaussian distribution.
The privacy loss measures the effect a single record's absence or presence has for M:
$$ \begin{equation} Z = \max \left(\log\left(\frac{P[M(D_1)=x]}{P[M(D_2)=x]}\right), \log\left(\frac{P[M(D_2)=x]}{P[M(D_1)=x]}\right)\right) \end{equation} $$
Where $D_2 = D_1 - \{d_{\text{new}}\}$.
For gaussian noise we have
$$ \begin{equation} \log\left(\frac{P[M(D)_{(\epsilon,\delta)}=x]}{P[M(D')_{(\epsilon,\delta)}=x]}\right) = \log\left(\frac{\frac{1}{\sqrt{2\pi\sigma}}e^{-\frac{(x-M(D)_{\text{clip}})^2}{2\sigma^2}}}{\frac{1}{\sqrt{2\pi\sigma}}e^{-\frac{(x-M(D')_{\text{clip}})^2}{2\sigma^2}}}\right) = \frac{M(D')_{\text{clip}}^2 - M(D)_{\text{clip}}^2 + 2x(M(D)_{\text{clip}} - M(D')_{\text{clip}})}{2\sigma^2} \end{equation} $$
We can plot the privacy loss against the different outputs $x$ from the gaussian $N$. We assume the worst case scenario in terms of maximum contribution from the new client, where all the clients feature values except the new one are $f > C$ and the new one $f_\text{new} < -C$, And we define $D_1$ as the dataset with all clients including the new one and $D_2 = D_1 - \{f_\text{new}\}$ then $M(D_2)_\text{clip} = C$ and $M(D_1) = \frac{n}{n+1}C - \frac{C}{n+1}$.
Figure 1 shows how the privacy loss $Z_N$ increases linearly with the distance from the middle of $M(D_1)_\text{clip}$ and $M(D_2)_\text{clip}$, $|x - \frac{M(D_1)+M(D_2)}{2}|$. Due to the fact that $x$ is unbounded $(-\infty, \infty)$ then the privacy loss is also unbounded and therefore $\epsilon$-DP (equation [1]) does not hold. But we can bound $x$ with some probability $1-\delta$ and then the privacy loss is also bounded with probability $1-\delta$. In Figure 1 the red dotted lines indicate the lower and upper bound of $x$ s.t.
$$ \begin{equation} p(\Phi^{-1}(0.005) < x < \Phi^{-1}(0.995)) = 0.99, \end{equation} $$
Where $\Phi^{-1}$ represents the inverse cumulative distribution function of the $N(0, \sigma^2)$ noise.
which means that with probability 0.99 our privacy loss is bounded by $\epsilon$ and therefore our example is $(\epsilon, \delta)$-DP secure (equation [2]).
This simple example was chosen to illustrate the basics of DP and the roles $\epsilon$ and $\delta$ have when defining the gaussian noise. In this example we assumed that we knew all values except one.
A more general formulation of how the Gaussian noise in DP is derived is presented in [3, Theorem 3.22]
Theorem A.1
Let $\epsilon \in (0, 1)$ be arbitrary.
For $c^2 > 2\ln(1.25/\delta)$, the
Gaussian Mechanism with parameter
$$ \begin{equation} \sigma = c\Delta_2M/\epsilon \end{equation} $$
is $(\epsilon, \delta)$ -differentially private.
Where $\Delta_2M = \max_{D,D'} |M(D) - M(D')|$
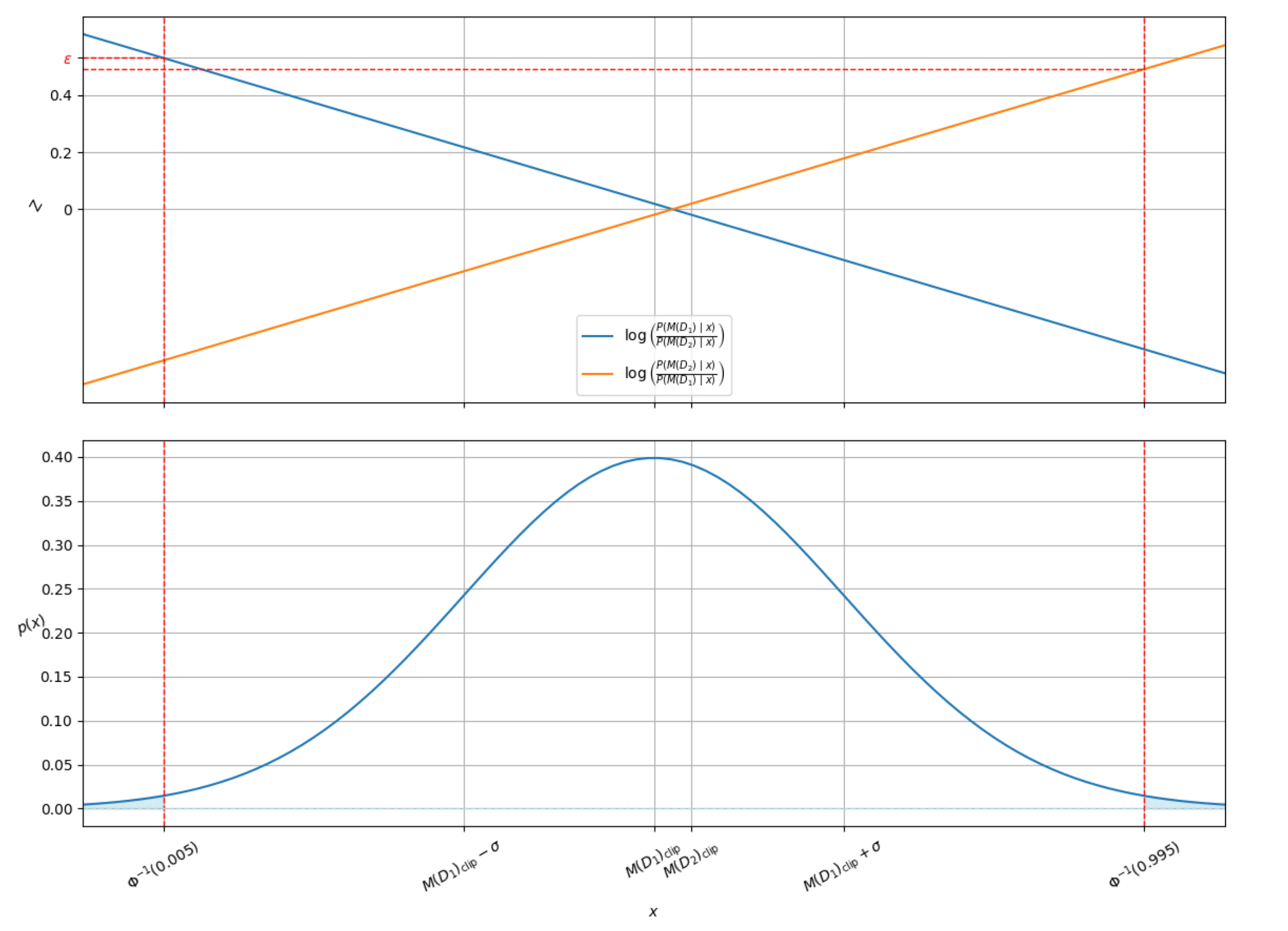
Figure 1: Top: Plot showing the privacy leakage for our example against the output x sampled from the distribution $M(D)_{(\epsilon,\delta)}$. Bottom: Plot showing the probability distribution of x. The blue shaded area represents the 0.5% tail of the distribution. The vertical red dotted line indicates the value of the inverse cumulative distribution function at 0.005, where the probability that x is less than this value is 0.5%.
Differential Privacy in the Federated Learning settings
In federated learning, ensuring privacy is crucial, as clients contribute sensitive data from distinct sources. Differential Privacy (DP) can be implemented at two levels to safeguard data:
-
Record-wise Differential Privacy (DP) focuses on protecting the privacy of individual data points or records within a client’s local dataset. This approach ensures that each record’s contribution to the client’s model update is masked, providing privacy for individual data points regardless of the client they belong to.
The most common implementation of record-wise DP is Differentially Private Stochastic Gradient Descent (DP-SGD)*, which involves clipping gradients and adding noise to the gradient updates. DP-SGD is applied locally on each client, ensuring record-level DP independently of other clients and the server. This means that, in theory, record-wise DP can be added to each federated learning client, allowing each client to independently set their desired (ε, δ) values for customized privacy guarantees.
-
Client-wise Differential Privacy (DP) aims to protect the privacy of an individual client’s entire data contribution in the federation, rather than each data point within that client’s dataset. This distinction is crucial in Federated Learning (FL) since each client typically represents a separate entity (e.g., a device or institution) with a local dataset. Client-wise DP ensures that the presence or absence of a client does not significantly affect the aggregated outcome, providing a privacy guarantee for each client as a whole.The formal definition resembles what we’ve seen in earlier DP contexts:
- Locally on each client before sending it to the server, known as Local Differential Privacy (LDP).
- Centrally on the server after aggregating updates, known as Central Differential Privacy (CDP).
$$ \begin{equation} P[M(N)\in X] \leq e^\epsilon P[M(N')\in X] + \delta, \quad \forall N' \quad [3] \end{equation} $$
where N represents the set of clients active in the federation round, and N′ is the "adjacent" dataset, differing from N by the inclusion or exclusion of a single client. In Client-wise DP, noise can be added to the local model update:
While LDP provides privacy by adding noise on each client, it can reduce the accuracy of the global model due to the higher noise level needed. CDP, on the other hand, allows for adding less noise overall by aggregating first, but it assumes trust in the server to perform the noise addition reliably.
For scenarios where client data is private—commonly the case in cross-device federated learning (FL) settings—client-level differential privacy (DP) is often preferred. The primary reason is that it protects the user's data as a whole, rather than individual records within the dataset, as is the case with record-level DP. Another advantage of client-level DP in cross-device settings is that the typically large number of participating clients reduces the impact of privacy noise on the overall model performance.
Conversely, in cross-silo FL settings, record-level DP is often more suitable. In these scenarios, the goal is usually to protect individual records within a client's dataset rather than the client’s contribution as a whole. Additionally, DP-SGD requires a sufficiently large dataset to mitigate performance degradation caused by the added privacy noise. Cross-silo setups, which generally involve fewer clients but larger datasets per client, are better suited for record-level DP as they can better absorb the effects of DP-SGD without significant loss in model accuracy.
Federated DP-SGD example in FEDn
Opacus is a DP library for PyTorch models that helps you transfer your existing PyTorch model training into a DP-secure one with minimal modifications.
What Opacus offers:
- Efficiency: Opacus can compute batched per-sample gradients instead of single sample microbatching.
- Privacy Counting: Keep track of your privacy budget at all times during training.
- Safety: Opacus uses a cryptographically safe pseudo-random number generator for its security-critical code. This is processed at high speed on the GPU for an entire batch of parameters.’
Very little is needed in terms of modifications to transfer an existing FEDn compute package to run DP-SGD with Opacus. Opacus also provides a set of examples on their page but we will take our own mnist-pytorch example and make it DP-SGD ready.
This blogpost will only highlight the part of the package that is different from the original mnist-pytorch. You can find the complete package here.
The first thing we have to do is adding Opacus to the python_env.yaml:
dependencies:
- opacus
Now we can modify the train.py script. The Privacy Engine will help us transfer our pytorch model, optimizer and data loader into an Opacus ready format.
from opacus import PrivacyEngine
privacy_engine = PrivacyEngine()
model, optimizer, train_loader = privacy_engine.make_private_with_epsilon(
module=model,
optimizer=optimizer,
data_loader=train_loader,
epochs=EPOCHS,
target_epsilon=EPSILON,
target_delta=DELTA,
max_grad_norm=MAX_GRAD_NORM,
)
You need to define the amounts of epochs you are planning to train your model on, you also have to set your target EPSILON and DELTA and your MAX_GRAD_NORM (Clipping norm C).
You will use Opacus BatchMemoryManager, a context manager to manage memory consumption during training. You will need to set a MAX_PHYSICAL_BATCH_SIZE dependent on your ram/vram on your machine.
from opacus.utils.batch_memory_manager import BatchMemoryManager
def train_dp(model, train_loader, optimizer, epoch, device, privacy_engine):
model.train()
criterion = torch.nn.NLLLoss() # nn.CrossEntropyLoss()
with BatchMemoryManager(
data_loader=train_loader,
max_physical_batch_size=MAX_PHYSICAL_BATCH_SIZE,
optimizer=optimizer
) as memory_safe_data_loader:
for i, (images, target) in enumerate(memory_safe_data_loader):
optimizer.zero_grad()
images = images.to(device)
target = target.to(device)
# compute output
output = model(images)
loss = criterion(output, target)
loss.backward()
optimizer.step()
The only thing that differs between training centralized DP-SGD in Opacus from training it in a federated setting is that you also need to save and load your Privacy account state in between the FL rounds.
Load the privacy engine state after you initiate PrivacyEngine()
if os.path.isfile("privacy_accountant.state"):
privacy_engine.accountant = torch.load("privacy_accountant.state")
At the end of the train function
torch.save(privacy_engine.accountant,'privacy_accountant.state')
We propose a per-round epsilon function that computes the epsilon to be spent in each round based on the current cumulative epsilon spent. This function updates the per-round epsilon using a square root scaling approach.
round_epsilon = np.sqrt((epsilon_spent/EPSILON*np.sqrt(GLOBAL_ROUNDS))**2+1)*EPSILON/np.sqrt(GLOBAL_ROUNDS)
The whole implementation can be found here: https://github.com/scaleoutsystems/fedn/tree/master/examples/mnist-pytorch-DPSGD
Reference
[1] Abadi, M., Chu, A., Goodfellow, I., McMahan, H. B., Mironov, I., Talwar, K., & Zhang, L. (2016). Deep Learning with Differential Privacy. arXiv. https://arxiv.org/abs/1607.00133
[2] Balle, B., Barthe, G., & Gaboardi, M. (2018). Privacy Amplification by Subsampling: Tight Analyses via Couplings and Divergences. arXiv. https://arxiv.org/abs/1807.01647
[3] Dwork, C., & Roth, A. (2014). The Algorithmic Foundations of Differential Privacy. Foundations and Trends in Theoretical Computer Science, 9(3-4), 211–407. Now Publishers. https://www.cis.upenn.edu/~aaroth/Papers/privacybook.pdf
Article by Mattias Åkesson, Senior Federated Learning Engineer