Input Privacy: Adversarial attacks and their impact on federated model training
Scaleout
Mar 25, 2024
Part 1 - The impact of label-flipping attack
This blog post emphasizes the significance of examining the adversarial attack landscape for federated model training as a separate entity from the centralized model training process. Using an attack example, we'll illustrate its effects on the global model and explore potential mitigation strategies in practical scenarios.
Prerequisites
If you require a quick refresher on federated machine learning, adversarial attacks, or input and output privacy, be sure to check out our previous blog posts:
Federated learning and adversarial attacks
The study of adversarial attacks on machine learning models has been extensively studied [1,2]. However, applying the insights gained from centralized model training to identify attacks and their remedies isn't a straightforward task in the context of federated machine learning. This challenge primarily stems from the unique nature of the federated learning process, where the aggregation step allows each client to contribute partially in each training round.
While studying this important topic, a significant aspect often gets overlooked: What constitutes realistic settings for designing an attack scenario? Recently, researchers at Google underscored that many studies on adversarial attacks frequently involve unrealistic settings [3]. For instance, attack scenarios that involve more than 20% of malicious clients are grounded in unrealistic settings. In such cases, the issue lies not within the federated training process itself but rather in the network or other infrastructure settings.
This is part 1 of the blog post series on attacks on federated machine learning and possible safeguard strategies. In this initial post, we'll delve into common attack types and introduce three well-known attacks in machine learning. Using a label-flipping attack as an example, we'll demonstrate its impact on the training process within federated settings. Stay tuned for future posts where we'll discuss additional attacks and mitigation strategies.
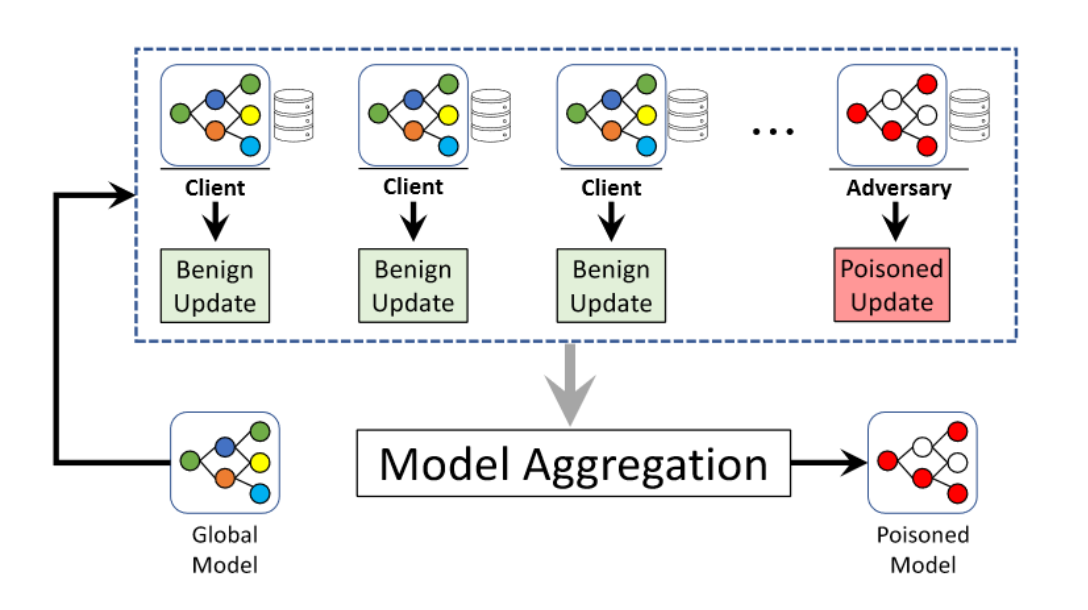
Figure 1 - Validation accuracy based on MNIST dataset using baseline (blue line - all honest clients) and compromised (orange line - 10 percent and green line - 20 percent malicious clients) federated model training.
Types of attacks
There are various ways in which the global model in federated settings can be poisoned, these methods can be categorized into Data Poisoning and Model Poisoning attacks. Both data and model poisoning attacks aim to decrease the final performance of the global model.
In Data Poisoning, the global model is influenced by directly manipulating the local training data on the individual client. Manipulating the training data can be done by switching the labels on the data or introducing noise to the input. On the other hand, in Model Poisoning, the client acts maliciously by directly manipulating the local model. Model poisoning can be executed by changing the weights or gradients of the local model.
Commonly known attacks
Here are three well-known attacks in the machine learning field. In this blog post, we'll dive into one of them – label-flipping attacks. We'll cover the other attacks in upcoming posts.
- Label flipping attack: A Label Flipping Attack is a type of data poisoning attack where the training data in one or many clients is manipulated. This means the attacker aims to perform a malignant update by deliberately mislabeling the training data. The simplest example of a poisoning attack by label flipping would be in a classification task, where all or targeted labels would be ”flipped” to the opposite one.
- Gradiate divergence attack: A Gradient Attack is an attack where the clients are performing model poisoning by manipulating the gradients. For example, clients manipulate only the gradient’s magnitude when inflating gradients.
- Backdoor attack: When performing a Backdoor Attack, the attacker introduces certain patterns or features in the training data. When this pattern or feature is present in new data, the attacker can influence which data will be classified to the targeted label. By implementing this attack locally, the idea is that the behavior will transfer to the global model when performing model updates.
Impact of label-flipping attack on federated learning training process
Experiment settings
For our experiments, we used the MNIST handwritten dataset along with the published Convolutional Neural Network (CNN) [4], employing the PyTorch framework for the training process. We adhered to standard settings, where 60,000 samples were allocated for training and 10,000 samples for testing. Additionally, the dataset on each client side is balanced and Independent and Identically Distributed (IID). We employed the FEDn SDK for federated model training, with FedAVG serving as the model aggregation scheme.
In this experiment, we exclusively focused on an untargeted attack, where malicious clients flipped all the class labels on their side.
The primary metric for evaluating the impact of the attack was model accuracy. Our ongoing extended analysis will include additional measures and explore a variety of scenarios, incorporating cases of imbalance and non-IID datasets and a range of different attacks.
The presented experiment encompasses the following three settings:
- All honest clients, serve as the baseline for federated model training and accuracy.
- 10 percent of malicious clients in the network with all labels flipped.
- 20 percent of malicious clients in the network with all labels flipped.
The decision to limit our consideration to up to 20 percent of malicious clients is grounded in the objective of studying the impact in realistic settings where attackers can be challenging to trace within the federated framework. This approach allows us to simulate scenarios that reflect the complexities and potential challenges faced in real-world federated learning environments.
Results and discussion
The presented results are derived from the average of three runs, where the dataset is shuffled in each run, maintaining the previously mentioned assumptions of balanced and IID partitions on each client side.
Figure 1 illustrates the validation accuracy plot based on all honest clients, 10 percent, and 20 percent malicious clients in the federation. The impact of up to 20 percent of malicious clients based on a label-flipping attack is marginal. The round-based model training approach, where each client contributes based on the local model and the aggregation process relies on the weighted average, by default restricts the impact of the attack on the global model. Thus, a label-flipping attack in its default form is not extremely harmful in the case of a federated machine learning training process in comparison to the centralized model training. However, mitigating any unexpected activities happening in the federation is still important.
While exploring the impact of the label-flipping attack, an intriguing observation emerged: in each round, it becomes challenging for malicious clients to diverge the local model by employing misleading labels. This is because, during each round, all clients receive a global model as a base model to continue the training process. This creates a local subspace within each client domain where malicious clients struggle, as the gradients and locally flipped datasets don't align well. The challenges faced by malicious clients are depicted in the training accuracy plot presented in Figure 2.
The struggle with malicious clients is primarily attributed to the FedAVG aggregation strategy applied on the server side in each round, allowing local models to only partially influence the global model. This iterative averaging process ensures that the majority (honest clients) have a higher influence on the global model. It's essential to note that this dynamic would change if the number of malicious clients surpasses the number of honest clients, but such a scenario would not align with a valid realistic setting.
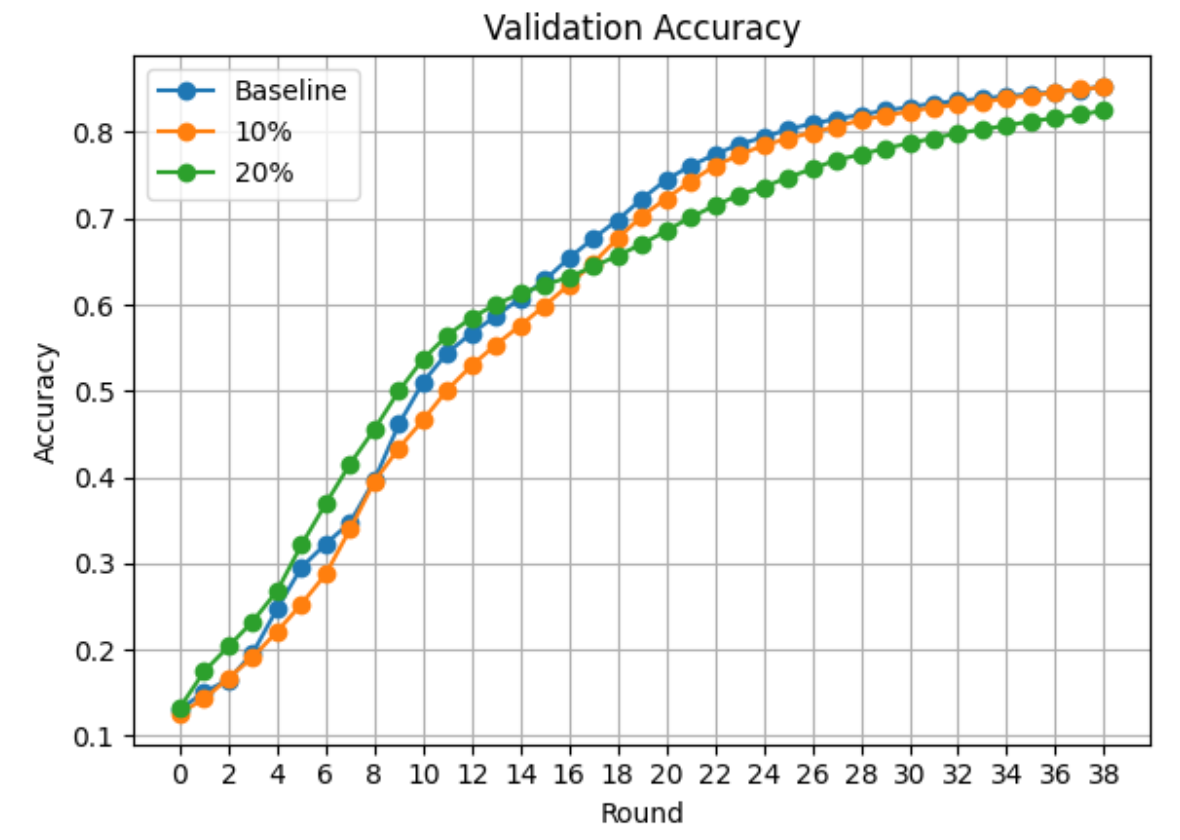
Figure 1 - Validation accuracy based on MNIST dataset using baseline (blue line - all honest clients) and compromised (orange line - 10 percent and green line - 20 percent malicious clients) federated model training.
Model training accuracy, often overlooked in presenting machine learning results, proves to be valuable in comprehending the client-side training process in federated settings. Figure 2 effectively underscores the federation has malicious/malfunctioning clients (orange and green lines). The overall low training accuracy is due to the continued incompatibility between the local training dataset based on flipped labels and the received global model in each round.
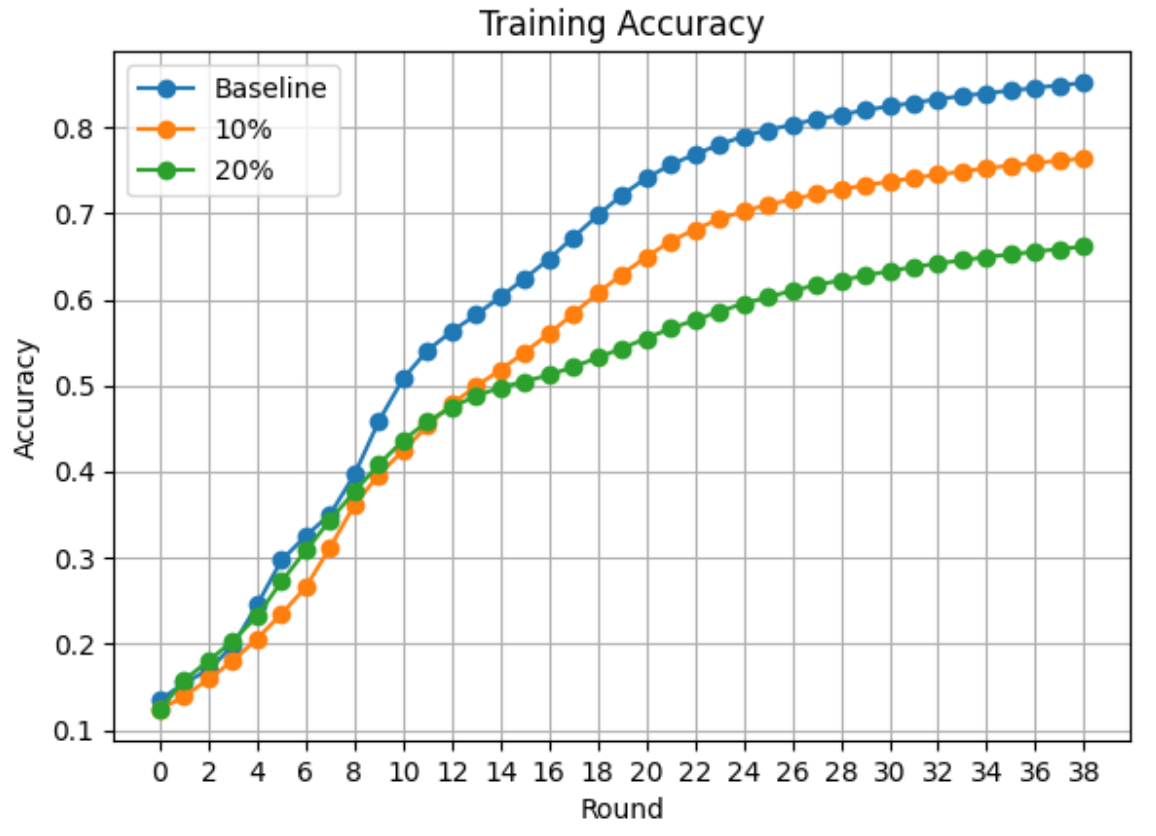
Figure 2 - Training accuracy plot based on baseline (blueline - all honest clients) and compromised (orange line - 10 percent and green line - 20 percent malicious clients) federated model training.
It is important to note that training accuracy can serve as a tool for identifying unexpected activities in the federation, which can be promptly addressed. This information can be integrated into the mitigation strategy to enhance the security of the federated training process. The notable difference in training accuracy, where training with all honest clients achieves close to 90 percent accuracy compared to 10 and 20 percent malicious clients resulting in less than 70 percent accuracy in the federation, highlights the significance of these measures.
Summary
The results indicate that the impact of adversarial attacks on federated machine learning differs significantly from centralized machine learning. The previously reported impact of the label-flipping attack on centralized model training does not apply to the federated model training process.
Acknowledgments
The results presented in this post are derived from the project report prepared for the computational science project course at Uppsala University.
References
- Yao Li, Minhao Cheng, Cho-Jui Hsieh & Thomas C. M. Lee (2022) A Review of Adversarial Attack and Defense for Classification Methods, The American Statistician, 76:4, 329-345, DOI: 10.1080/00031305.2021.2006781
- Chakraborty, A., Alam, M., Dey, V., Chattopadhyay, A. and Mukhopadhyay, D. (2021), A survey on adversarial attacks and defences. CAAI Trans. Intell. Technol, 6: 25-45. https://doi.org/10.1049/cit2.12028
- V. Shejwalkar, A. Houmansadr, P. Kairouz and D. Ramage, "Back to the Drawing Board: A Critical Evaluation of Poisoning Attacks on Production Federated Learning," 2022 IEEE Symposium on Security and Privacy (SP), San Francisco, CA, USA, 2022, pp. 1354-1371, doi: 10.1109/SP46214.2022.9833647.
- MNIST using PyTorch https://www.kaggle.com/code/geekysaint/solving-mnist-using-pytorch [Access date: 19th Feb, 2024 ]