Vertical Federated Learning with FEDn
Scaleout
May 16, 2025
We would like to thank Vinnova, Sweden’s innovation agency, for funding this project.
TL;DR: Vertical Federated Learning allows clients with different but complementary features for the same samples to collaborate and train a machine learning model without sharing their data.
FEDn now implements split learning as an approach for the vertical case. Split learning enables hospitals, banks, and other organizations to leverage all available information while maintaining patient or customer data privacy.
Horizontal Federated Learning
When one talks about federated learning, one usually refers to horizontal federated learning (horizontal FL). In horizontal FL, every client holds data that has the same features, but the individual samples (records) differ between clients.

Example:
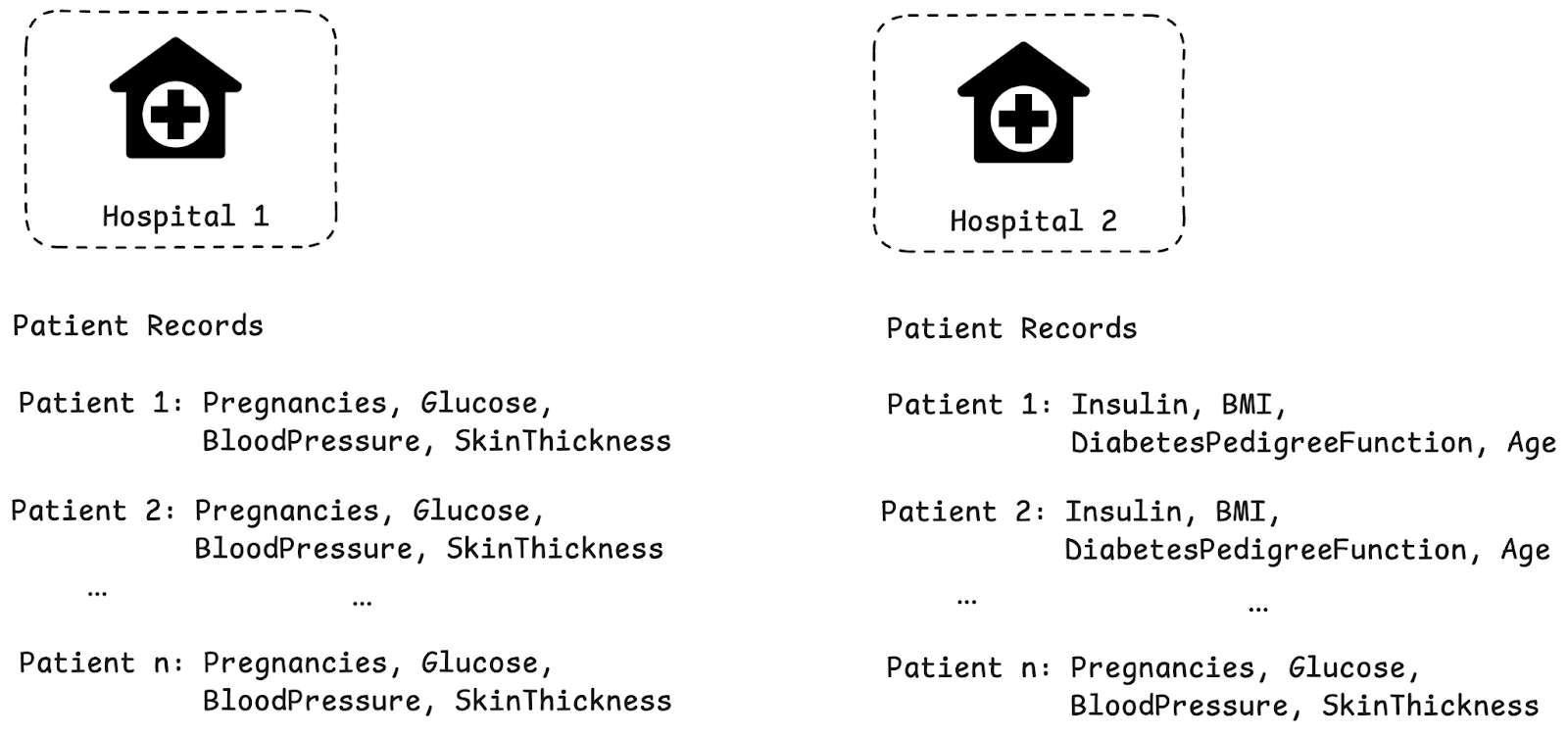
- Hospitals might collect the same information for each patient, such as age, blood pressure, BMI, etc. Hospital 1 might have records of one group of patients, while hospital 2 has records for different patients.
Vertical Federated Learning
Vertical federated learning (Vertical FL) applies to situations where different clients hold information on the same set of individuals, but with different features. While the samples (e.g., patients or customers) are the same across client datasets, the available features differ between clients. Usually it is also the case that only one client has access to the labels.

Examples:
- Hospital 1 might store age and blood pressure about a patient, while hospital 2 stores other information about the same patient. Combining these features can improve disease prediction
- Bank 1 might store transaction data about customers, while bank 2 collects credit card usage details for the same customers. Combining this information can improve credits score prediction
Vertical FL is used when parties have different, but complementary features for the same data samples. Vertical FL allows them to build more accurate predictive models while preserving data privacy.
A concrete example: The Pima Indians Diabetes Database dataset
Let’s make the hospital use case from above more concrete: Consider two hospitals that store complementary data about the same patients. They want to train a machine learning model that predicts whether a patient has diabetes or not. As each hospital stores useful features to predict diabetes, they want to use all available information about each patient. But due to privacy reasons, they are not allowed to share the data with each other. As we now know, vertical FL is a solution to circumvent this problem.
The Pima Indians Diabetes Database dataset contains diagnostic measures of patients that can be used to predict whether a patient has diabetes or not. Have a look at the kaggle link to get an overview over the dataset and to understand the features and their meaning.
For our use case, we split the dataset across two hospitals (clients). Each hospital now stores a subset of the available features of the dataset, as visualized in the figure below.
Centralized case:
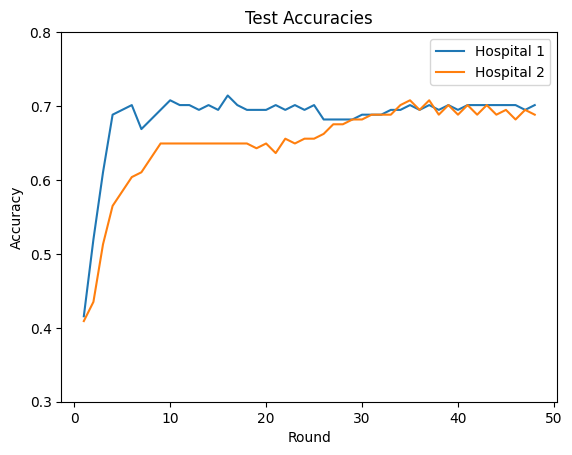
Let’s assume that the hospitals do not collaborate, i.e., each hospital trains their own machine learning model to predict diabetes based on their available features. For this, each hospital trains its model (we use a small neural network). The following test accuracies are achieved:

Collaboration through vertical FL:
The two hospitals now decide to collaboratively train a machine learning model using all patient data. As their data is highly sensitive, they are not allowed to directly share the data with each other. However, the hospitals believe that all features are relevant to predict whether a patient has diabetes or not. They use vertical FL to collaboratively train a predictive model without sacrificing the patient's data privacy. For this, they use FEDn’s implementation of split learning (it is explained in a section below).
In the table and plot below, we observe that collaborative training between hospitals using vertical federated learning leads to higher test accuracy (0.72) compared to individual (centralized) model training at each hospital (0.68 & 0.7). That is because the hospitals now make use of more available features, which they could not have without vertical FL. For comparison purposes, the test accuracy using centralized training (0.74) is also provided. We can see that the accuracy of vertical FL approaches that of the centralized training but, as expected, stays below it.

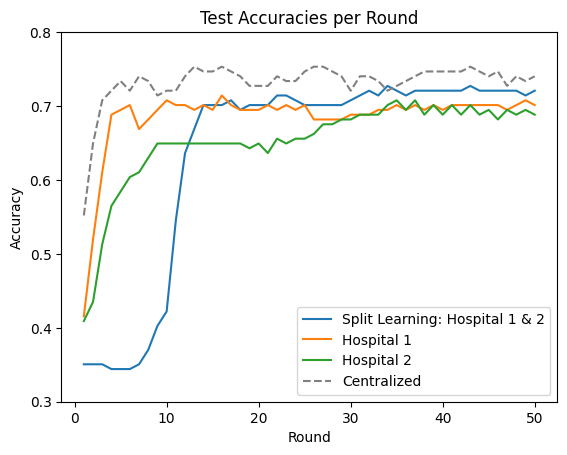
In summary, vertical FL enhances model accuracy, improving the prediction of whether a patient has diabetes. This approach can, of course, be applied to other domains as well.
Vertical FL in FEDn
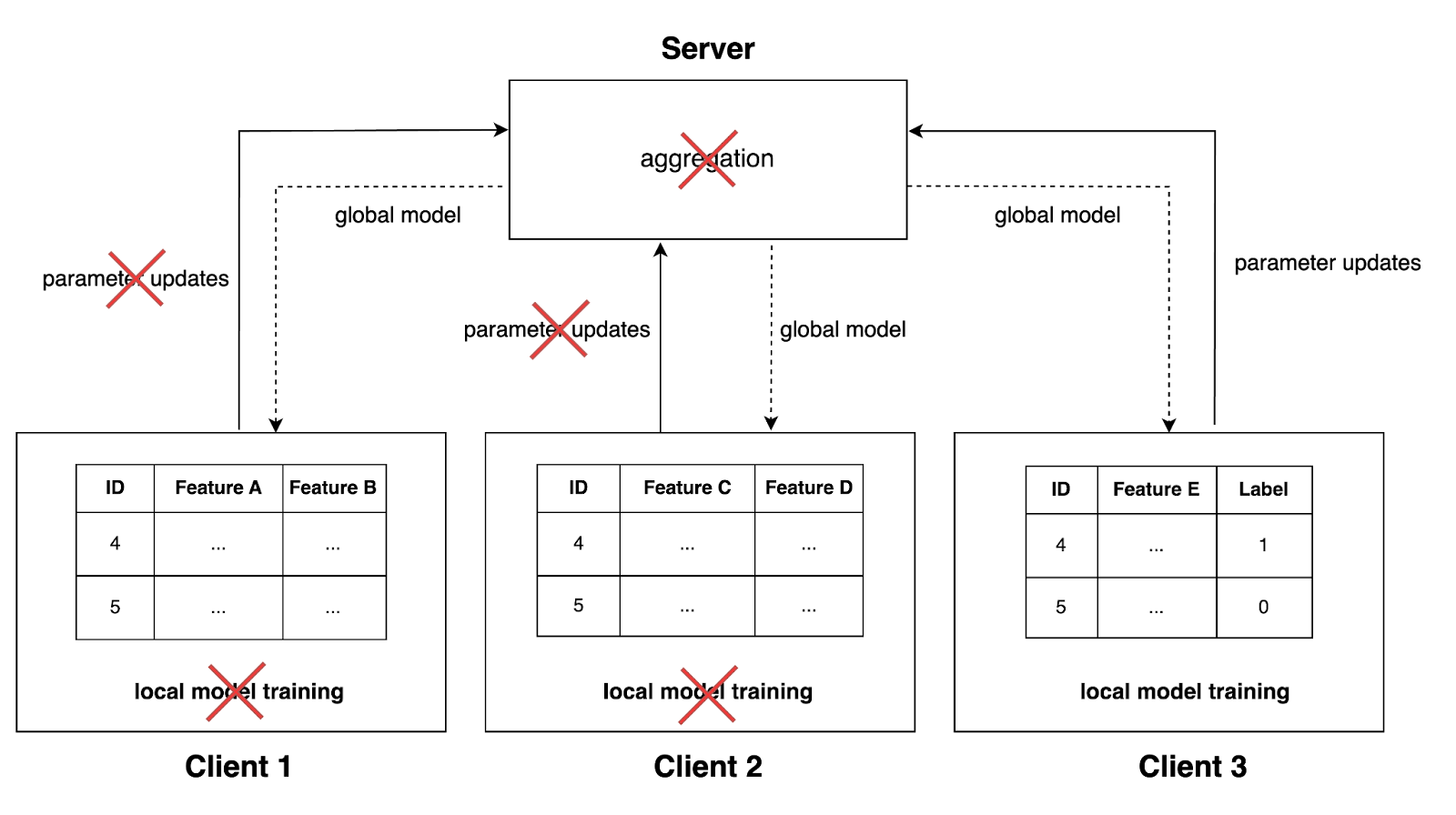
Why standard FL fails in the vertical case
As we now know, clients store data with different features in the vertical case. Further, it usually is the case that only one client has access to the labels. Because of this, one cannot calculate a loss on the client side and update the local model parameters. Subsequently, no parameter updates can be sent to the server, and no server-side aggregation can occur. Even if all clients had access to the labels, it would not make sense to aggregate models that were trained on different features.
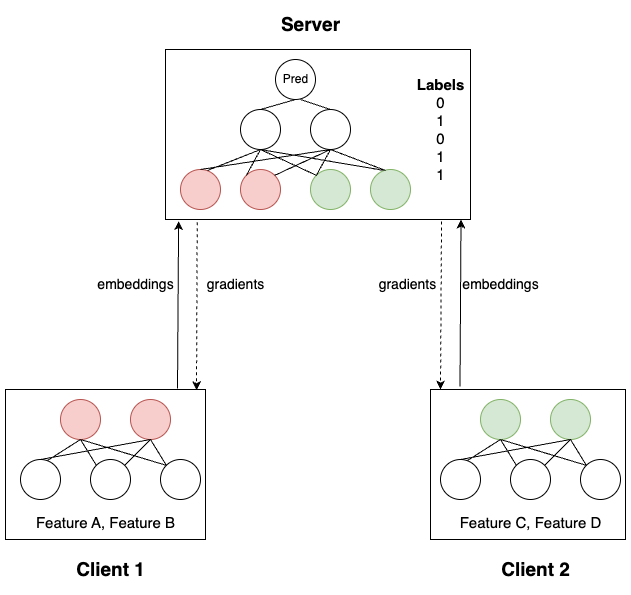
Split Learning
FEDn now supports split learning with label sharing, one approach to vertical FL. It works fundamentally different from standard horizontal FL. The implementation assumes that labels are shared with the server.
A neural network is split across participating clients and the server (this approach is therefore also referred to as “SplitNN”). The steps are the following:
- Clients perform a forward pass based on their local network and send the embedding to the server
- The server concatenates the embeddings and continues the forward pass based on its local partial neural network. As it holds the labels, it can calculate the loss from the output it generates.
- The server performs backpropagation and sends the obtained gradients to the clients
- The clients continue the backpropagation and update the parameters of their local partial neural networks.
Repeat for a given number of training rounds.
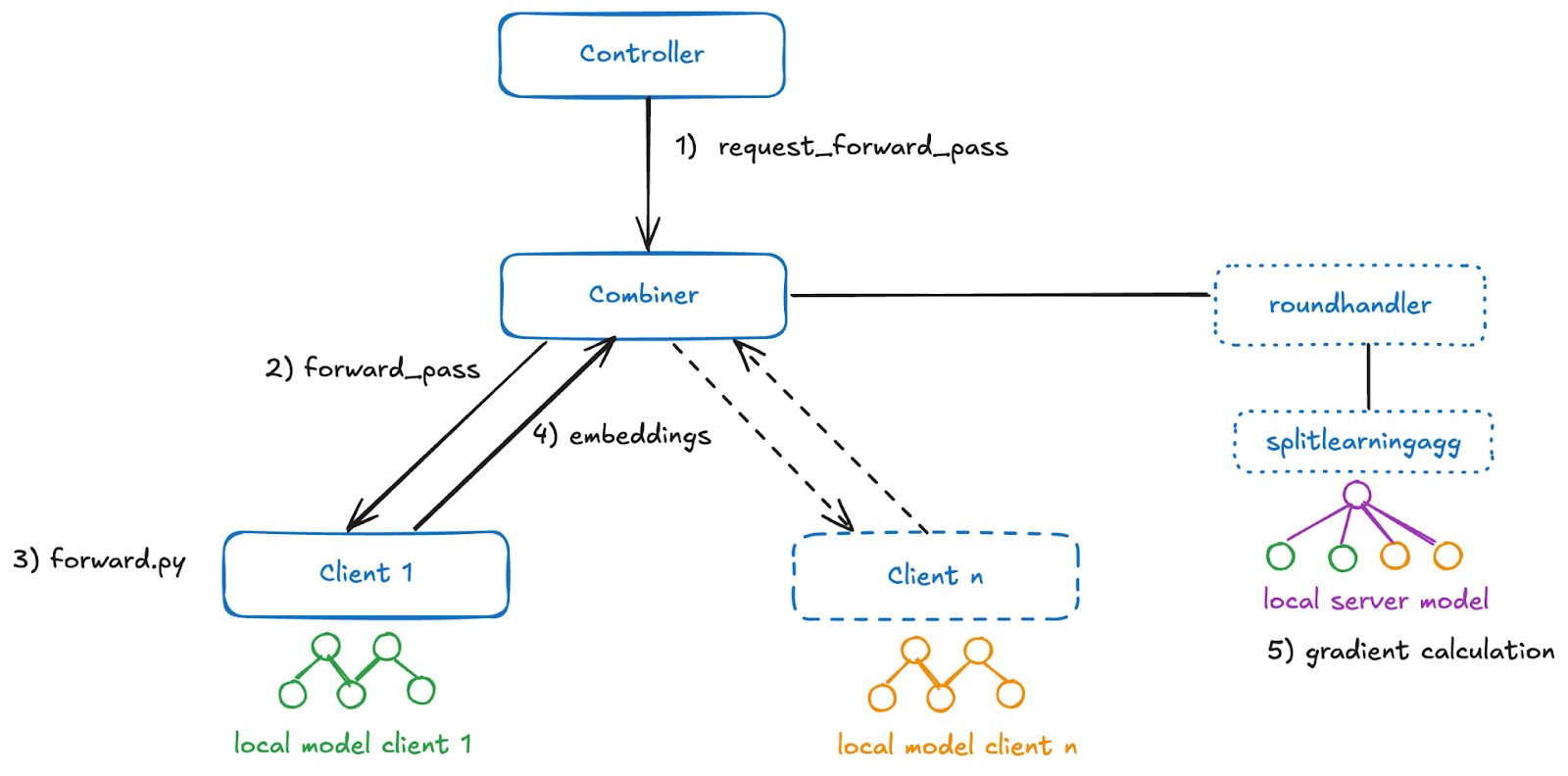
FEDn implements the following split learning logic, where one round consists of the following steps:
- Forward pass
- Backward pass
- Validation (optional)
This process is repeated for a certain number of rounds.
In the forward pass, clients calculate the embeddings based on their local model and send them to the combiner. The splitlearning aggregator is part of the combiner. Here, the embeddings are concatenated in correct order and the forward pass continues based on the defined server model. The loss is calculated based on the labels that need to be made available to the combiner. Then, the gradients are calculated and the local parameters are updated.
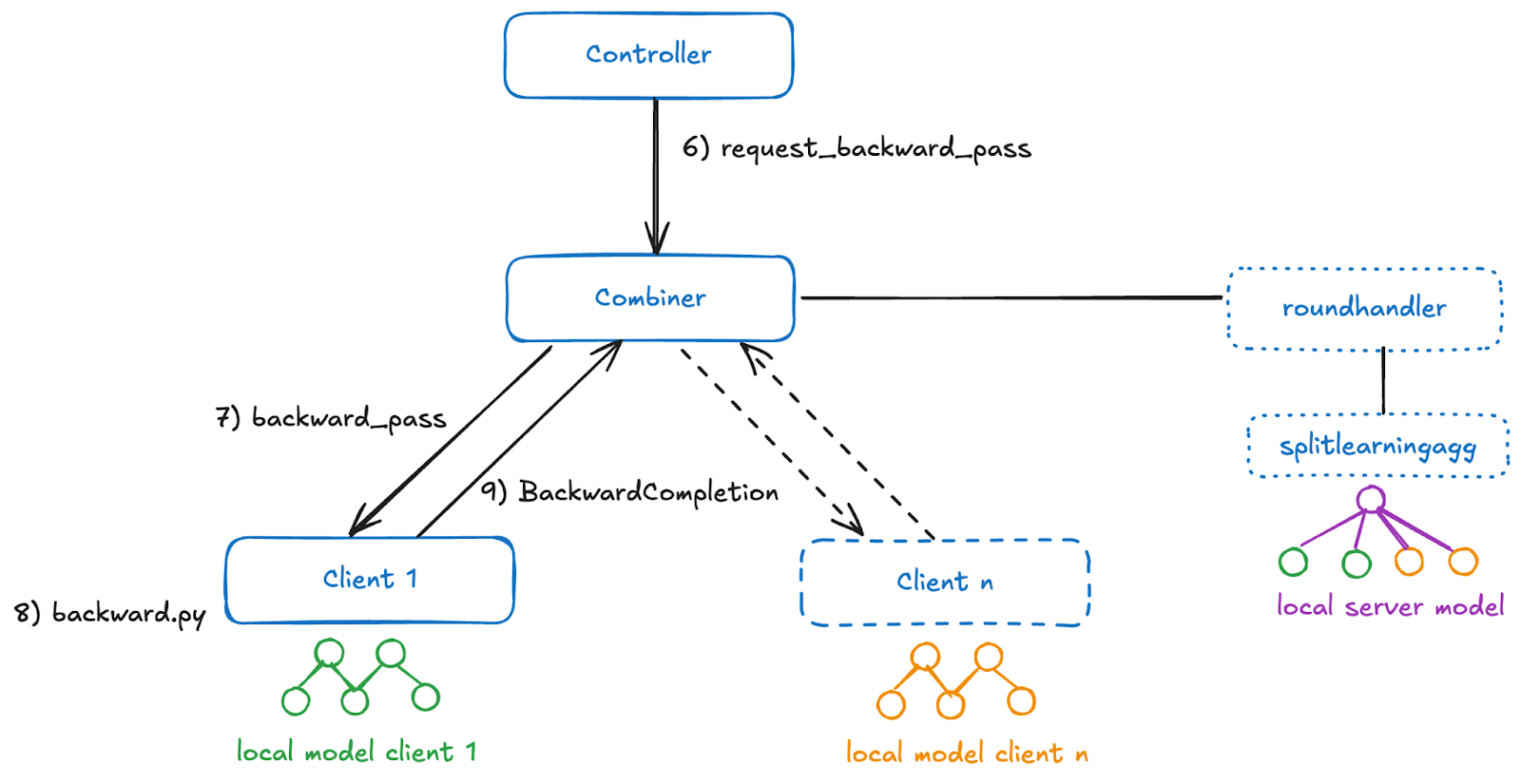
In the backward pass, the gradients are sent back to the clients. The clients continue the backward pass and update their local model parameters. After this is done, they send a message to the controller indicating that the process is finished.
Validation on a defined test set follows the same flow as the forward pass, but does not update any model parameters.
How to use Split Learning with FEDn
You can find the example from above implemented here. To run it yourself, follow the steps described in the readme. Feel free to adapt it to your own use-case and do not hesitate to reach out to us if you have any questions by joining our discord channel.