Scaleout VisionKit is a specialized toolkit designed to streamline federated and personalized computer vision tasks at the edge, focusing on improving model robustness, accuracy, and generalizability by leveraging image data collected directly from edge devices like drones, vehicles, and IoT sensors. It provides developers with modular workflows for scalable pre-training, fine-tuning, data selection, and human-in-the-loop annotation, integrating computer vision models with edge infrastructure for adaptive AI systems.
Core Components
Federated Learning Workflows: VisionKit enables self-supervised and supervised federated learning, allowing models (e.g., ResNet, ViT backbones) to be pre-trained in a decentralized manner across fleets of devices and organizations without aggregating raw data centrally.
Model Integration: Pre-trained backbones can be imported into object detectors such as Faster R-CNN and DETR. And various versions of YOLO (YOLOv8, YOLOv11) are integrated, supporting real-time and privacy-preserving object detection applications for surveillance, autonomous driving, quality control in manufacturing, and more.
Active Data Selection on the Edge: The toolkit incorporates edge-first pipelines to filter, score, and select valuable data from video streams before annotation and training, using techniques like SSIM for redundancy reduction, uncertainty scoring with object detectors, and diversity filtering via embedding similarity.
End-to-End Customizability: VisionKit offers templates for fully customizable active learning workflows, seamless integration with locally deployed labeling tools (e.g., Label Studio), and robust support for modern edge hardware like Nvidia Jetson devices.
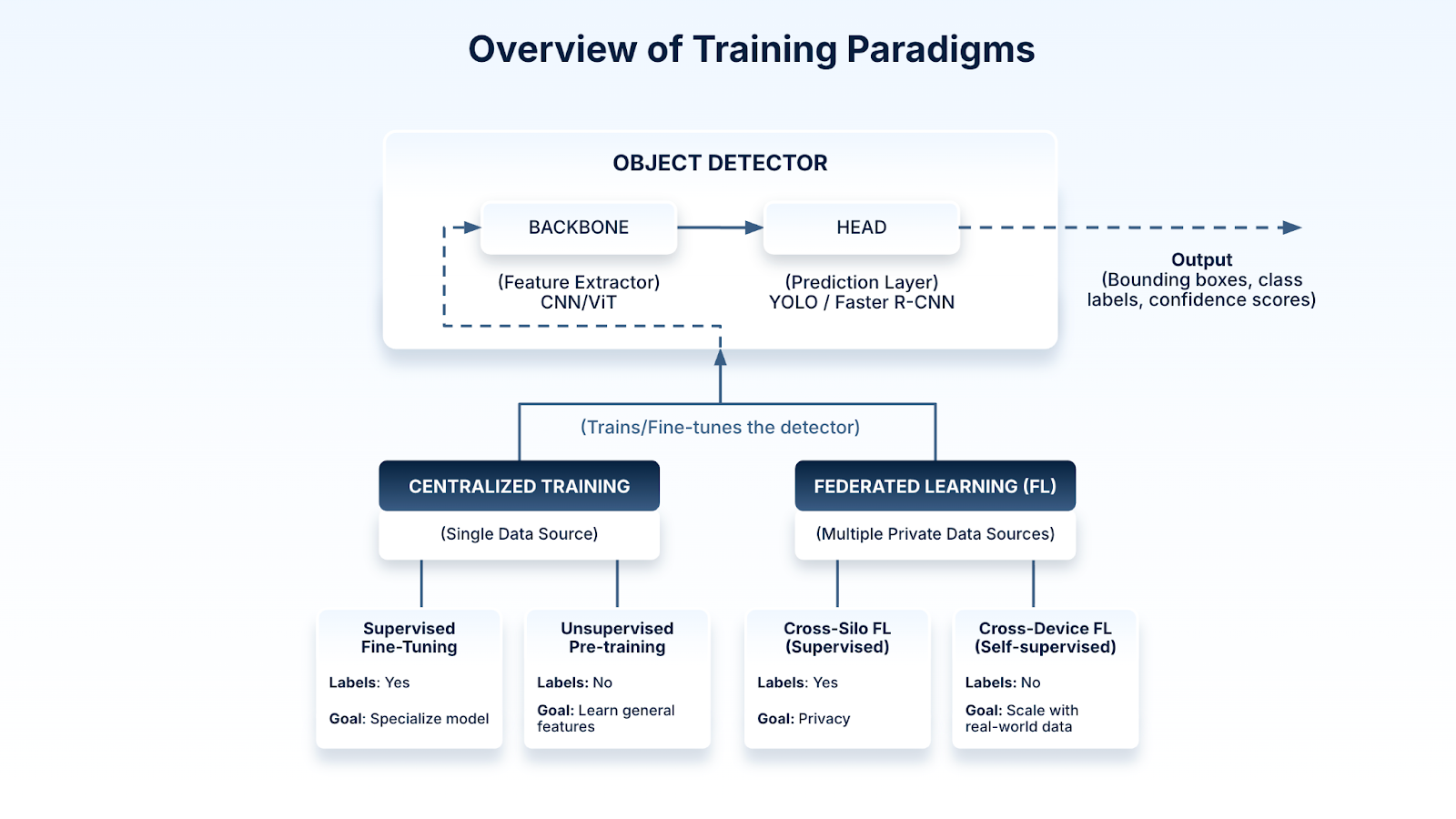
Figure 1: A comparison of centralized vs. federated learning methods for training a modern object detector.
Federated Learning and Privacy
Federated learning in VisionKit addresses key industry needs of privacy, efficiency, and adaptability by allowing devices to train models locally and share only model updates, preserving data confidentiality while collaboratively improving AI performance. Key benefits include enhanced data privacy in regulated domains such as healthcare, reduced data transfer latency, stronger model generalization via diverse data sources, and operational resilience in challenging environments like conflict zones.
Technical Workflow Details
Frame Selection Pipeline: Automated extraction of the most informative video frames using scene change detection (SSIM), model uncertainty scoring (YOLO), and embedding diversity filtering (cosine similarity), reducing annotation and training overhead while maintaining data breadth.
Self-Supervised Pre-Training: VisionKit supports frameworks like SimSiam and DINOv2, promoting federated self-supervised learning where models learn useful data representations on-device and can later be fine-tuned with a small subset of labeled data.
Edge Deployment: Pipelines are designed for deployments on systems-on-chip like Nvidia Jetson, leveraging local compute for model training, data selection, and annotation.
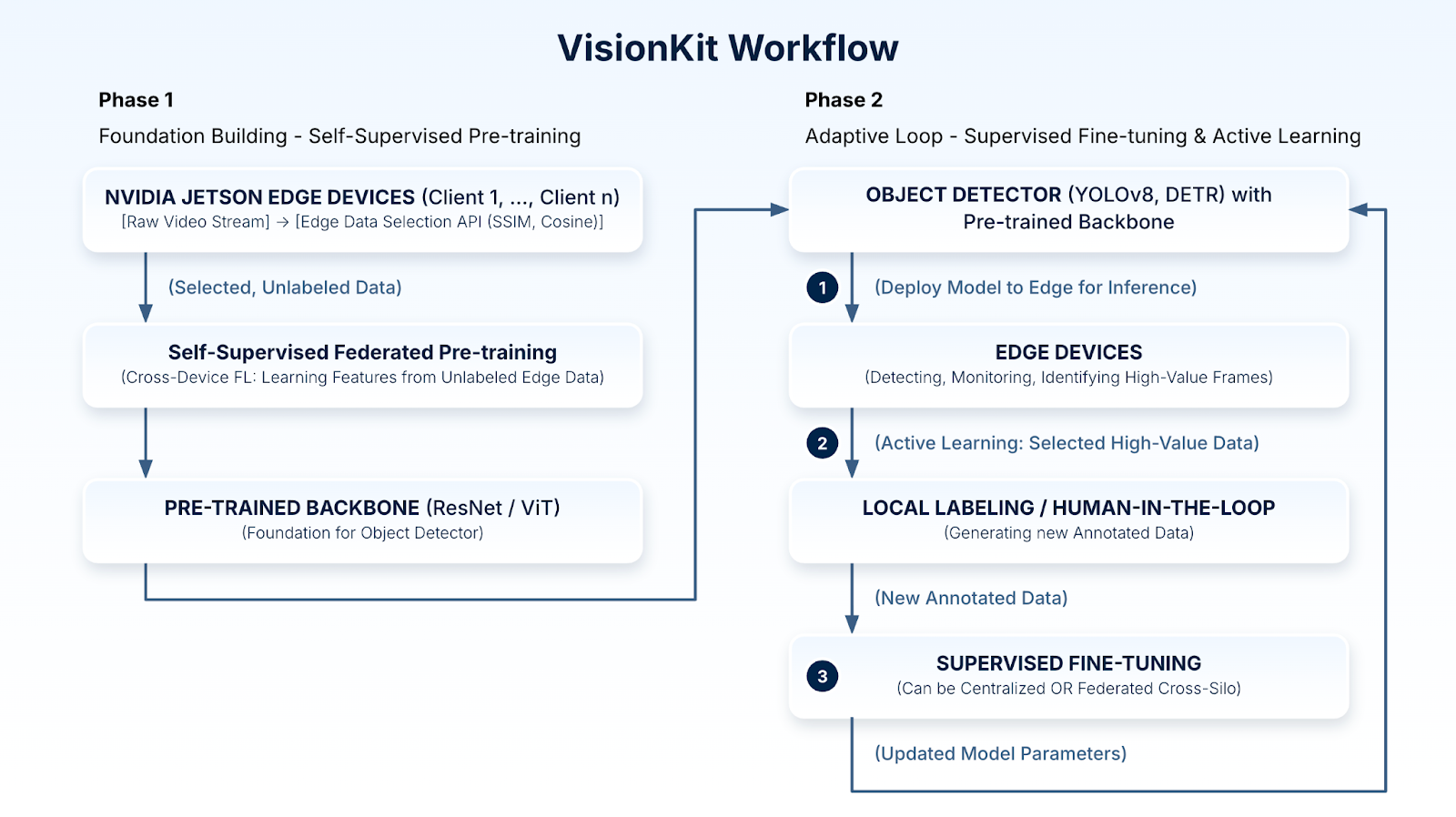
Figure 2: The Scaleout VisionKit Adaptive AI Workflow. This active learning loop shows the model being (1) deployed to the edge to find valuable data, (2) annotated by a human-in-the-loop, and (3) used to fine-tune the system for continuous improvement.
Example Implementations
Manufacturing: Automated defect detection and quality control across facilities using federated YOLO models.
Autonomous Vehicles: Self-supervised federated learning is used to train models using vast unlabeled datasets from vehicles, improving tasks like object detection while handling massive data volumes and privacy restrictions.
Medical Imaging: Federated self-supervised learning unlocks siloed medical data across hospitals, enabling privacy-preserving model pre-training on unlabeled scans and reducing annotation needs for segmentation tasks.
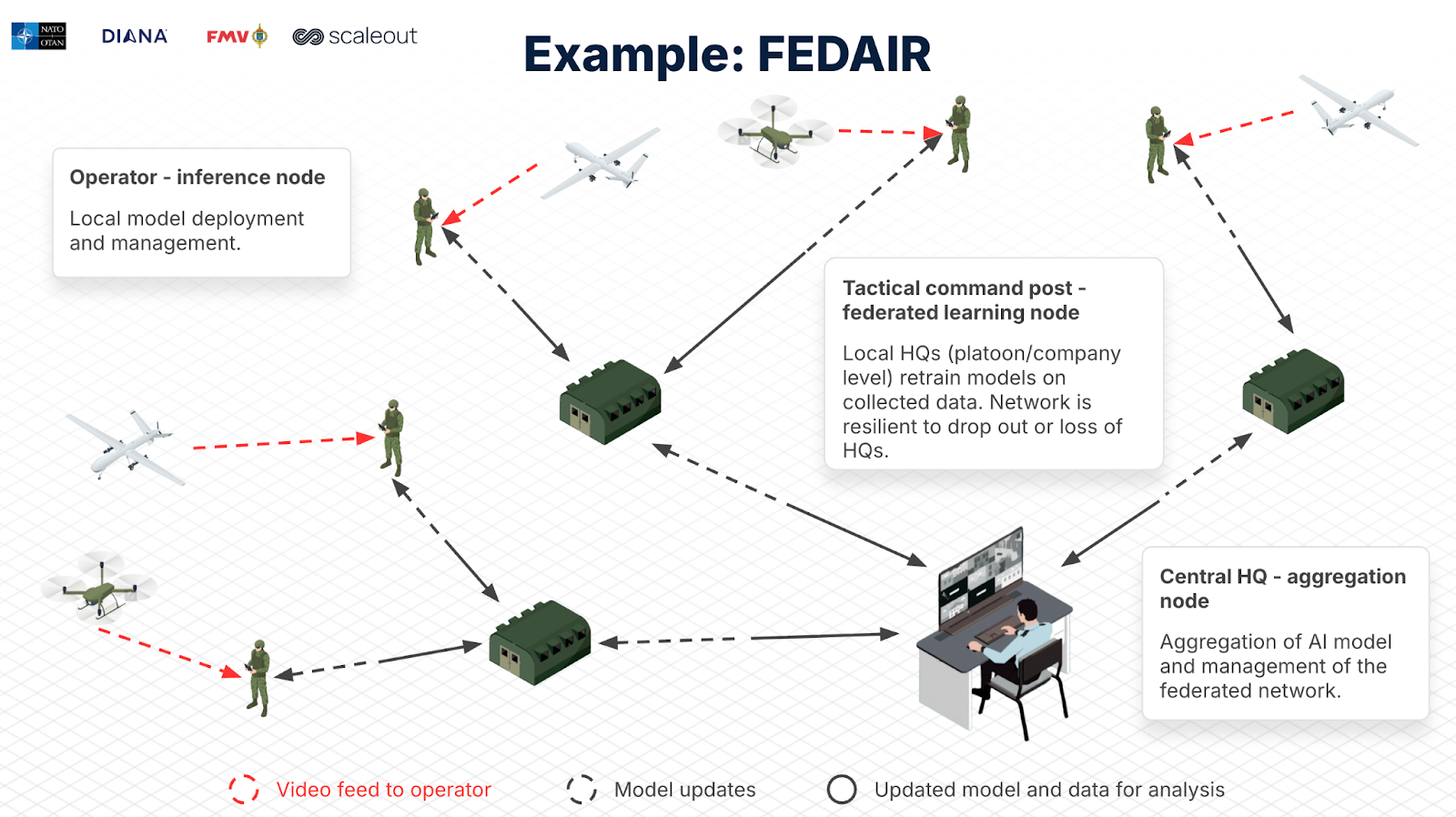
Defense Applications: The FEDAIR project (part of NATO’s DIANA Programme) demonstrates federated intelligence, enabling ML model updates in contested environments without centralized data aggregation, crucial for security and resilience.
Figure 3: The NATO FEDAIR project. Each unit is part of a federated machine learning network managed centrally. When units retrain their models, the updates are sent and aggregated at the central level. This enables all operators and participants to use continuously updated models that reflect the entire network’s data, without transferring sensitive raw data. The network is also resilient to outages of any duration.
Summary
Scaleout VisionKit, part of the Scaleout Edge platform, offers a comprehensive development kit for federated computer vision, delivering adaptive learning, privacy-preserving data workflows, and modular edge-to-cloud AI integration. It supports supervised, self-supervised, and active learning with advanced video frame selection, real-time annotation, and robust model deployment, serving applications from industry to defense.
Combining federated learning with mixture-of-experts models to enable scalable, efficient, and context-aware fleet intelligence, allowing vehicles and devices to collaboratively train specialized computer vision models while preserving privacy, reducing communication costs, and supporting real-time edge decision-making. https://www.scaleoutsystems.com/post/fleet-intelligence-with-mixture-of-experts-federated-learning
Integrating YOLO object detection with federated learning enables privacy-preserving, real-time, and bandwidth-efficient AI systems for applications like defect detection, wildlife monitoring, and autonomous vehicles, allowing collaborative model training without sharing sensitive data while improving robustness and performance across diverse environments. https://www.scaleoutsystems.com/post/federated-learning-for-object-detection-using-yolo
%201.svg)